
In this article we will discuss how to correctly size the hardware resources of a 3 node Proxmox VE hyper-converged cluster and how to get an estimate for the best possible solution.
The cluster we’ll be sizing below consists of 3 nodes and 2 switches.
It’s very important to understandi how the hyperconverged cluster works.
1. The logic behind the project
A few introductory remarks before starting:
- The cluster consists of three servers (also called nodes or hypervisors).
- The hyper-converged storage space, at the core of the 3 node cluster, is calculated differently than CPU and RAM resources.
- Cluster load is represented by a Virtual Machine (VM) and a Container (CT).
- The cluster must continue to operate without service interruption even if a node and/or switch goes down.
Sizing will be done considering a fundamental characteristic:
A cluster makes sense because it has Fault Tolerance characteristics.
Meaning a cluster consisting of 3 nodes and 2 switches will work without interruption, even in the event of a node or switch failure.
If you are unable to run VMs and CTs on two of the three nodes due to lack of hardware resources, the the cluser concept is lost.
Such scenario can and should be avoided with correct hardware sizing.
These Fault Tolerance characteristics indicate that all hardware requirements of the virtual machines and containers will have to run on 2 nodes and 1 switch.
This means that, in our example, you can afford losing one node and one switch without affecting how the resources work.
2. Essential parameters for cluster sizing
First, we need to retrieve the information necessary to carry out the sizing.
The essential parameters to size the cluster are as follows:
- A description of the resources (VM and/or CT). We give the resource a name as in the table below.
- Type of operating system: Windows / Linux, etc…
- Disk space in GB.
- Number of physical cores.
- RAM in GB
How is hyper-converged space calculated?
For enstanace, if we have 3 nodes and each node has 4TB of total storage space, the total hyper-converged space of the cluster will be 4TB.
This is because in a 3 node cluster, the replication factor is 3. Therefore data, by definition of hyper-convergence, is replicated three times within the cluster.
Core and RAM calculation is different, as the resources of each node add up.
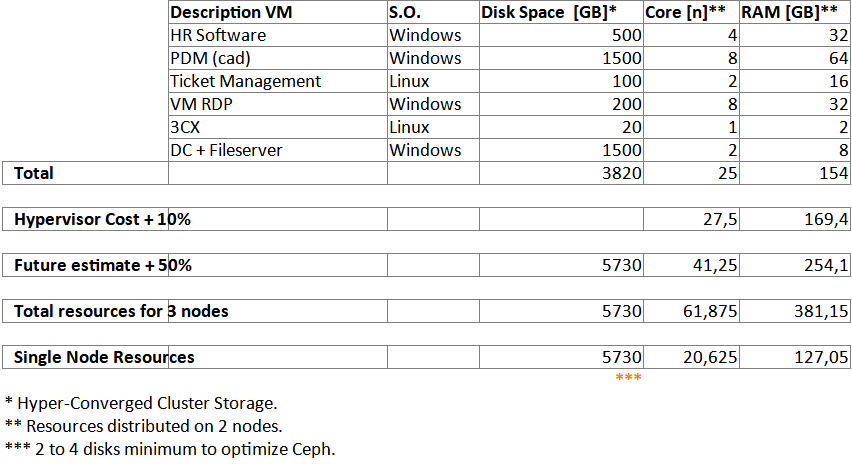
Let’s consider the cost in terms of RAM and CPU resources of the hypervisor which we have estimated at more or less 10%.
We then estimate a 50% load growth. We calculate a growth in demand of more or less 50% from the date of installation until the end of life of the solution.
You can make your own estimations by entering data that best satisfies your case.
We increase Cores and RAM enough to run the VMs and CTs on 2 of the 3 nodes of the cluster.
In our example, we take Core and RAM, respectively 41 and 254 and divide by a factor of two.
After rounding up, we get the data present on the “Single Node Resources” row. We thus obtain the resources of the “Single Node Resources”.
Note that the same does not apply to storage, as the total space is already replicated 3 times.
The size we see on the “Single Node Resources” line regarding disk space will already be that of the single node.
To obtain optimal disk performance, note that Ceph works very well with at least 4 disks per node.
However, operation is guaranteed even with 2 discs.
3. Cluster hardware upgrade
Now let’s look at hardware upgrades and how they impact sizing.
In our previous example, we estimated a 50% increase in hardware resources for the same system load request.
What could happen if this 50% estiamte is not done from the start?
Se non prevediamo questo 50% fin da subito, cosa potrebbe succedere in futuro?
We have two scenarios:
Scenario 1:
You can increase hardware resources by increasing either disk space and/or RAM by simply adding parts.
As for the disks and RAM, the process is trivial.
When it comes to CPU cores, it is not that simple. You need to unmount the CPU and mount compatible one.
It is feasible but technically more complex.
Scenario 2:
Increase the number of nodes.
This is a powerful cluster feature since all you need to do is to add a node to the cluster to expand storage space, RAM and CPU.
Therefore, correctly providing networking (switch) is crucial, since it is an integral part of the system’s performance.
4. Choosing the switch
In addition to connecting virtual machines or containers to the world, switches also manage the cluster’s hyper-convergence.
Keep in mind that every time you write data on a VM or a CT, it passes through the networking (network cards and switches), which cannot and must never be a bottleneck.
For this purpose, right from the beginning, you need to chose a switch that will be suitable for both current and future needs.
5. Choosing the disks
The choice of storage tends to be that of choosing between SSD and NVMe.
We receive many requests for clusters with rotative SATA or SAS type hyper-converged storage, due to low cost of them.
Unfortunately, due to the poor performances, a hyper-converged solution with these technologies is not feasible.
One of the main reasons is that during operation, OSD realignments can occur which cause performance peaks.
During such peaks the spinning disk is not fast enough to provide enough I/O to the VM and CT to perform required hyper-convergence tasks.
All of this causes Ceph errors, generating cluster stability and performance issues.
Spinning disk technology has problems. For this reason its use is strongly discouraged.
6. How to request a quote
Once the hardware characteristics of the single node have been defined, we can proceed to request an estimate to have an fiancial quantification of the investment.
If you are not certain about the choices, we suggest leaving the default selection.
In any case, each quote is verified before being sent out.
Based on our example’s speficications we’re working with the 3 Node Hyper-Converged Proxmox VE Cluster – S1B
We said that about 21 Cores are needed. In this case we round them down.

Then we move on to RAM memory. The number that comes closest is 128GB

Since this is a production system we choose the annual subscription – Proxmox VE Community,

The OS will be installed on two Raid 1 128GB drives. This is already the default.

Storage is around 6TB. We choose the closest denomination, in this case 8 TB.

As mentioned above, networking is an integral part of the cluster, therefore data written on a virtual machine, wherever it is located, is written in real time on all three. Data will then pass from the network.
From testing, and from data easily available online, we can easily see that SSD or NVMe disks can easily saturate a 10 Gbit connection.
For this reason the cluster must be equiped with at least 25 Gbit cards and switches to avoid bottlenecks.
The S1B cluster is equipped with SSD disks and often 25 GB network cards.
We’ll use two redundant switches. Each node will be connected to switch 1 and switch 2 to ensure redundancy.
Switches will be stacked together. Considering 25GB hyper-converged networking between nodes, we’lll use a 40Gbit stack to avoid bottlenecks.
Switches will need to support the Stack protocol as well as node NIC aggregation protocols.
In this will enable you to take advantage of all the speed of the installed hardware and total redundancy, both on the switches and on the NICs.

At the end of the configuration, click on “Add to Quote”.
We will be happy to help you with the configuration and in choosing the model that best suits your needs.
7. 2 Node Hyper-Converged Cluster
There are articles and videos online discussing hyper- convergence with 2 node clusters.
Currently, hyper-convergence with Proxmox VE is not feasible with 2nodes.
We strongly doubt the efficiency and resilience of solutions from other brands that market 2 node solutions as technically they do not seem feasible solutions.
The solutions we tested turned out to be unsuitable because, while sometimess providing the promised redundancy, in some failure scenarios they were unable to “understand” the state of the nodes, thus causing serious system malfunctions.
There are also technical limitations therefore there is no reliable solution that can be considered suitable for a 2 node production environment.

