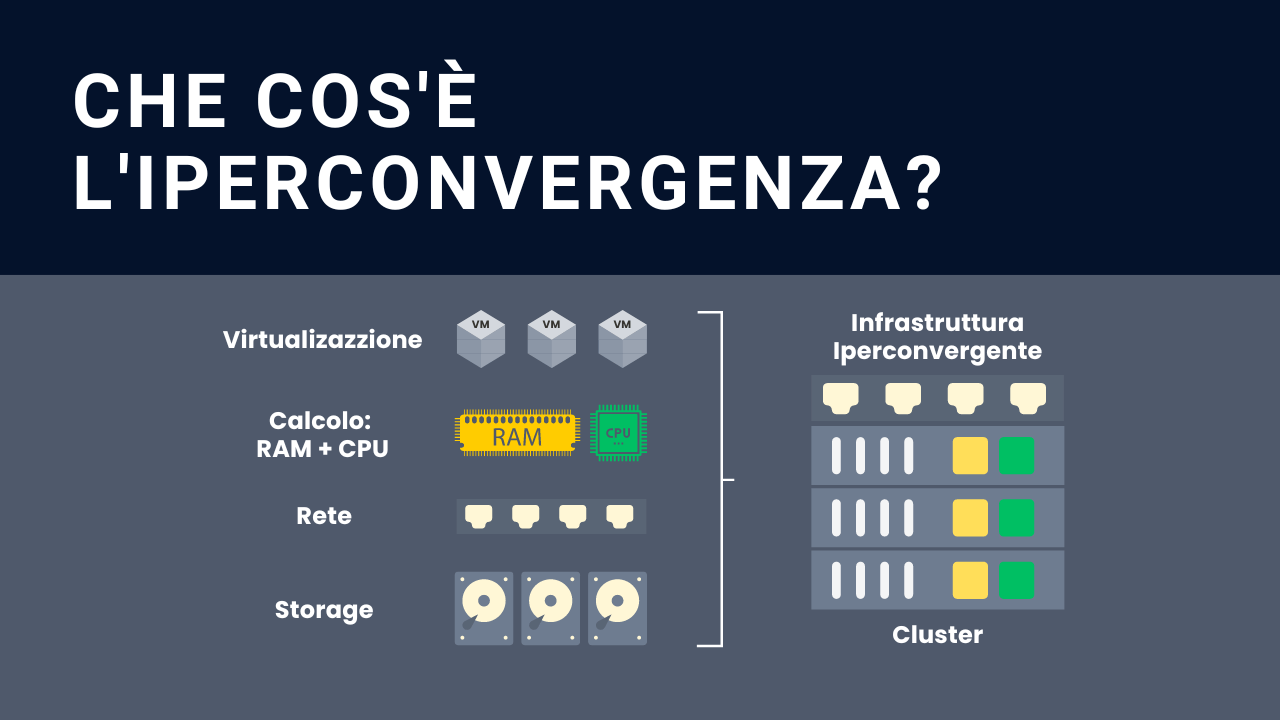
In questo articolo vedremo come effettuare correttamente il dimensionamento delle risorse hardware di un cluster iperconvergente Proxmox VE a 3 nodi ed infine in che modo ottenere il preventivo per la miglior soluzione possibile.
Il cluster che verrà dimensionato di seguito sarà composto da 3 nodi e 2 switch.
Come prerequisito per comprendere a pieno quanto segue, occorre conoscere i principi di funzionamento di un cluster iperconvergente.
Con il corso Proxmox VE puoi approfondire le tua conoscenza del funzionamento del cluster iperconvergente a 3 nodi.
Il dimensionamento del cluster Prxmox VE a 3 nodi
1. Il ragionamento alla base del progetto
Prima di partire facciamo alcune premesse importanti:
- il cluster è composto da tre server (anche detti nodi o hypervisor).
- lo spazio storage iperconvergente, che sta alla base del Cluster a 3 nodi, si calcola diversamente rispetto alle risorse CPU e RAM.
- Il carico del nostro cluster è rappresentato da Virtual Machine (VM) e Container (CT).
- Il cluster dovrà continuare a funzionare senza interruzione di servizio anche se si verifica la perdita di un nodo e/o di uno switch.
Il dimensionamento verrà fatto considerando una caratteristica fondamentale:
Il cluster ha senso solo se sussistono le caratteristiche di Fault Tolerance.
Ciò significa che un cluster composto da 3 nodi e 2 switch potrà funzionare senza interruzioni anche in caso di non funzionamento di un nodo e/o uno switch.
Se ci troviamo nella situazione di non poter eseguire le nostre VM e CT su due dei tre nodi per mancanza di risorse hardware, vuol dire che perdiamo lo scopo del cluster.
Questa situazione potrà e dovrà essere evitata con un corretto dimensionamento hardware.
Queste caratteristiche di Fault Tolerance, ci portano a considerare che tutto il fabbisogno hardware delle nostre macchine virtuali e container, dovrà poter girare su 2 nodi e 1 switch.
Questo vuol dire che, in questo esempio, potrò perdere al massimo un nodo ed uno switch senza inficiare il funzionamento del carico.
2. I parametri indispensabili per dimensionare il cluster
Come prima cosa dobbiamo recuperare le informazioni necessarie per effettuale il dimensionamento.
Impostiamo una tabella e collezioniamo le informazioni come nella tabella che segue.
I parametri indispensabili per dimensionate il cluster sono fondamentalmente:
- una descrizione delle risorse (VM e/o CT). Diamo un nome alla risorsa come nella tabella che segue.
- il tipo di sistema operativo: Windows / Linux, ecc…
- lo spazio disco espresso in GB.
- il numero dei core fisici necessari.
- RAM in GB
Come si calcola lo spazio iperconvergente?
Accedi al Corso Proxmox VE Gratuito per approfondire il calcolo dello spazio in un sistema iperconvergente.
All’interno del corso si trova un file Excel già impostato che aiuterà ad organizzare le informazioni e ottenere il dimensionamento corretto. L’esempio riportato sotto si basa su questo strumento.
Di seguito facciamo un esempio pratico di calcolo di spazio iperconvergente:
Se abbiamo tre nodi e ogni nodo, ha 4 TB di spazio storage totale, lo spazio iperconvergente totale del cluster sarà 4 TB.
Questo perché in un Cluster a 3 nodi, il fattore di replica è 3. Lo spieghiamo in dettaglio nel nostro corso gratuito.
Ciò significa che i dati, proprio per definizione di iperconvergenza, vengono replicati tre volte all’interno del cluster.
Il calcolo è diverso per i Core e la memoria RAM, in quanto le risorse di ogni nodo si sommano.
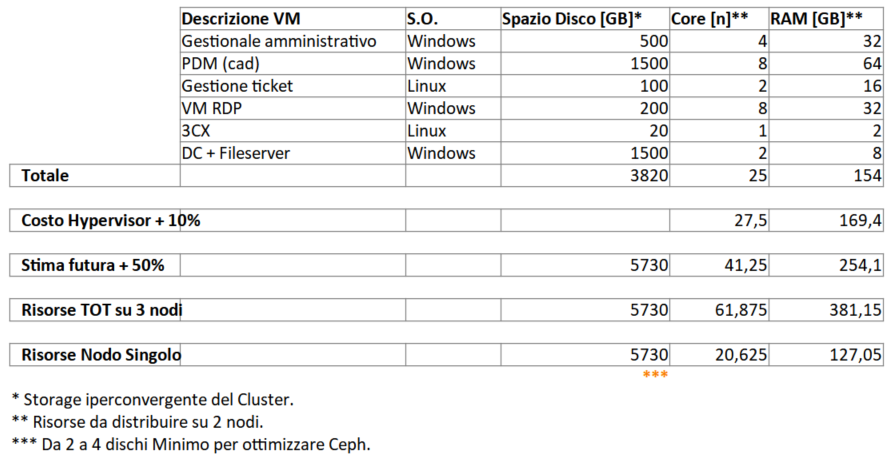
Sarà necessario poi considerare il costo in termini di risorse RAM e CPU dell’hypervisor che abbiamo stimato più o meno in un 10%.
Abbiamo poi fatto una stima futura di crescita del carico del 50%. Calcoliamo una crescita del fabbisogno più o meno del 50% dalla data dell’installazione fino a fine vita della soluzione.
Ovviamente, ognuno può simulare la propria situazione andando a mettere il dato che più soddisfa la propria condizione.
Andiamo a maggiorare i Core e la RAM di un fattore sufficiente a far girare le nostre VM e CT su 2 dei 3 nodi del Cluster.
Nel nostro esempio il calcolo che faremo è prendere Core e RAM, rispettivamente 41 e 254 e divideremo per un fattore due.
Otterremo così, dopo un arrotondamento, i dati presenti sulla riga “Risorse Nodo Singolo”. Otteniamo così le risorse del “Risorse Nodo Singolo”.
Attenzione che per lo storage non vale la stessa cosa in quanto lo spazio totale è già replicato 3 volte.
La dimensione che vediamo sulla riga “Risorse Nodo Singolo” in merito allo spazio disco sarà già quella del singolo nodo.
Per ottenere prestazioni ottimali in termini di performances disco, segnaliamo che Ceph raggiunge performances con almeno 4 dischi a nodo.
Confermiamo che anche con 2 dischi il funzionamento è garantito.
3. Upgrade hardware del Cluster
Consideriamo ora l’upgrade hardware e come impatta il tema del dimensionamento.
Nel nostro esempio precedente, abbiamo fatto una stima considerando un aumento del 50% delle risorse hardware a fronte di una medesima richiesta del carico dei sistemi.
Se non prevediamo questo 50% fin da subito, cosa potrebbe succedere in futuro?
Abbiamo 2 scenari due scenari:
Scenario1:
Si possono aumentare le risorse hardware andando ad aumentare o lo spazio disco e/o la RAM semplicemente aggiungendo delle parti.
Per quanto riguarda i dischi e RAM, l’operazione è banale.
Per quanto riguarda i Core della CPU occorre comprendere che non è per nulla semplice. Occorrerà smontare la CPU e montarne un’altra compatibile. Operazione fattibile ma tecnicamente più complessa.
Scenario 2:
Aumentare il numero di nodi.
Questa è una proprietà potente dei cluster perché basterà aggiungere un nodo all’interno del cluster per espandere spazio storage, RAM e CPU.
Sarà quindi determinante prevedere correttamente il networking (switch), il quale è parte integrante del funzionamento di tutto il sistema.
4. La scelta dello switch
In un cluster iperconvergente, gli switch non danno soltanto la possibilità alle macchine virtuali o ai container di essere connesse con il mondo, ma gestiscono tutta la parte di iperconvergenza.
Occorre ricordare che tutte le volte che scriviamo un dato su una VM o un CT, esso passa attraverso il networking (schede di rete e switch), che non potrà e non dovrà mai essere un collo di bottiglia.
Per questo motivo dobbiamo scegliere uno switch che già dall’inizio risulterà adeguato alle nostre esigenze attuali e future.
5. Scelta della tecnologia disco
Un altro aspetto da considerare nei cluster è la scelta della tecnologia disco. Tendenzialmente la scelta dello storage può ricadere su due tipi di tecnologie: SSD o NVMe.
Riceviamo molte richieste di cluster con storage iperconvergente di tipo rotativo SATA o SAS, per via del basso costo di questi supporti.
Purtroppo per via delle scarse performances fornite da questi supporti non è realizzabile una soluzione iperconvergente con queste tecnologie.
Una delle motivazioni principali è che durante il funzionamento e l’uso dei sistemi, possono verificarsi dei riallineamenti degli OSD che causano dei picchi di performance.
Durante questi episodi il disco rotativo non riesce ad essere sufficientemente veloce per fornire sufficiente I/O a VM e CT ed espletare il compito richiesto dall’iperconvergenza.
Tutto ciò causa errori su Ceph, generando problemi di stabilità e di performance dei cluster.
La tecnologia dei dischi a rotazione presenta dei problemi. Per questo è fortemente sconsigliato utilizzarla.
6. Come ottenere un preventivo
Una volta definite le caratteristiche hardware del singolo nodo procediamo alla richiesta del preventivo in modo da avere una quantificazione economica dell’investimento.
Se non sei in grado comprendere uno o più menù, ti consiglio di lasciare la selezione di default.
In ogni caso ogni preventivo viene validato internamente prima di essere inviato.
Scopri la gamma dei Cluster Iperconvergenti Proxmox VE a 3.
In base alle specifiche del nostro esempio scegliamo la soluzione Cluster Iperconvergente Proxmox VE a 3 Nodi – S1B.
Abbiamo detto che servono circa 21 Core. In questo caso arrotondiamo per difetto.

Poi passiamo alla memoria RAM. Il numero che sia avvicina di più è 128 GB

Visto che si tratta di un sistema di produzione scegliamo l’abbonamento annuale – Proxmox VE Community,

Il sistema operativo si installerà su due dischi da 128 GB in Raid 1. È già così di default.

Lo storage è circa 6 TB. Scegliamo il taglio più vicino, in questo caso 8 TB.

Come abbiamo già detto, il networking è parte integrante del cluster, pertanto il dato che viene scritto su una macchina virtuale, ovunque essa si trovi, viene scritta in real time su tutti e tre i nodi.
I dati passeranno quindi dal networking.
Da test effettuati, e dai dati facilmente reperibili online, si può facilmente vedere che una batteria di dischi SSD o NVMe può saturare facilmente una connessione 10 Gbit.
Per questo motivo sarà necessario dotare il cluster di schede e Switch almeno a 25 Gbit per non avere colli di bottiglia.
Il Cluster S1B è dotato di dischi SSD e tendenzialmente dotato di schede di rete 25 GB.
Utilizzeremo quindi due switch ridondanti. Ogni nodo andrà collegato allo switch 1 e allo switch 2 per garantire la ridondanza.
Gli switch saranno collegati in Stack tra loro. Considerando il networking iperconvergente a 25 GB tra i nodi, per evitare colli di bottiglia, utilizzeremo uno Stack a 40 Gbit.
Gli switch dovranno supportare il protocollo di Stack oltre ai protocolli di aggregazione delle NIC dei nodi.
In questo modo si riuscirà a sfruttare tutta la velocità dell’hardware installato e una ridondanza totale, sia sugli switch che sulle NIC.

Alla fine della configurazione, sarà sufficiente cliccare su “Aggiungi a Preventivo” per ottenere una quotazione del Cluster Proxmox selezionato.
In ogni caso saremo lieti di aiutarti nella configurazione e nella scelta del modello più adatto alle tue esigenze.
7. Cluster a 2 nodi iperconvergenti
Online ci sono articoli e video che parlano di iperconvergenza con cluster a 2 nodi.
In questo momento l’iperconvergenza con Proxmox VE non è fattibile con due nodi.
Dubitiamo fortemente anche dell’efficienza e della resilienza di soluzioni di altri brand che commercializzano soluzioni 2 nodi in quanto tecnicamente non ci sembrano soluzioni realizzabili.
Tutte le soluzioni che abbiamo testato sono risultate inadatte in quanto, pure fornendo la ridondanza promessa (anche questo non sempre), in alcuni scenari di guasto non sono state in grado di “capire” lo stato dei nodi, causando così gravi malfunzionamenti del sistema.
Tecnologicamente, esistono dei limiti tecnologici, pertanto non esiste una soluzione affidabile che possa essere considerata adatta per un ambiente di produzione con soli due nodi.