
In this article we clarify 5 things to know about the functioning of the 2 Node Proxmox VE Cluster.
5 Things to know about 2 Node Proxmox VE Cluster
1. What happens if a node fails
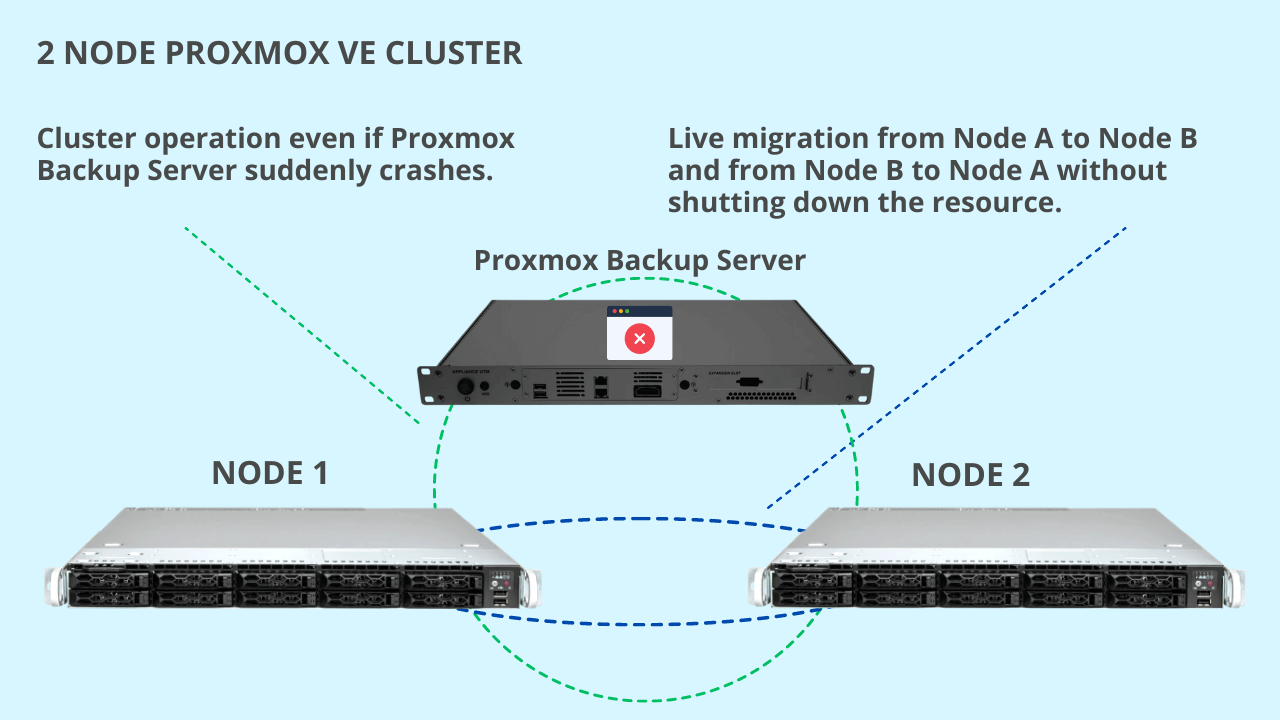
Starting from the scheme with the PBS (Proxmox Backup Server) node, Node A and Node B.
Assuming that one of the three nodes fails.
Absolutely nothing happens at a cluster level, because you have to think of the 2 node cluster as if it were a 3 node cluster from a quorum perspective.
For example, if Proxmox Backup Server suddenly fails, absolutely nothing happens. The important thing is to keep at least two nodes runnign out of 3, as per Proxmox specifications.
Furthermore, you can easily migrate a virtual machine from Node A to Node B and from Node B to Node A in live mode, i.e. without shutting down the resources.
For example, a running VM can be migrated live from Node A to Node B, regardless of whether the replicas are scheduled or not.
If the replicas are scheduled, when migrating a virtual machine from Node A to Node B, replication tasks will automatically be reversed, so it will be from Node B to Node A.
2. How to determine the amount of storage

Let’s take a practical example to understand how much storage to allocate.
Suppose we have 6 virtual machines on the Cluster: 3 VMs on Node A and 3 VMs on Node B, and each virtual machine (for simplicity) is 100GB.
Overall, about 300 GB will be allocated to Node A’s storage. Same thing for node B.
Assuming to schedule the replicas of all VMs, from Node A to Node B, and vice versa. 300GB for VMs and 300GB for replicas must be considered on each node.
The total of each node will therefore be 600 GB.
The file system will try to optimize the space, so it won’t be 600 GB but it will be a little less. We’re going a little bit larger to be safe, so we’re looking at 600GB.
It is not requited to have replicas of all resources (VM or CT) from Node A to Node B.
For example, if one of the virtual machines on Node A is a machine with unimportant services and therefore you don’t want to replicate to Node B, (Node B could perhaps be considered as purely a backup node).
In this case, resource replication tasks are not created, and consequently 100GB must be removed from the replicas. So overall on Node B (destination host) there will no longer be 600GB but 500GB occupied.
It therefore depends on how the Cluster is set up and in particular the replicas: if you want everything to be redundant from Node A to Node B and vice versa.
A span-metric calculation could always consider double the allocated storage.
3. Resource recovery: how long it takes to get back up and running
The time it takes to restore a backup from Proxmox Backup Server to the nodes depends on the hardware used and in particular on the switches, network cards and above all on the types of disks implemented for PBS storage.
However, a very spannometric order of magnitude, it can range from one minute to 20 minutes.
4. Recover a VM from a ransomware attack
To restore a machine from a rans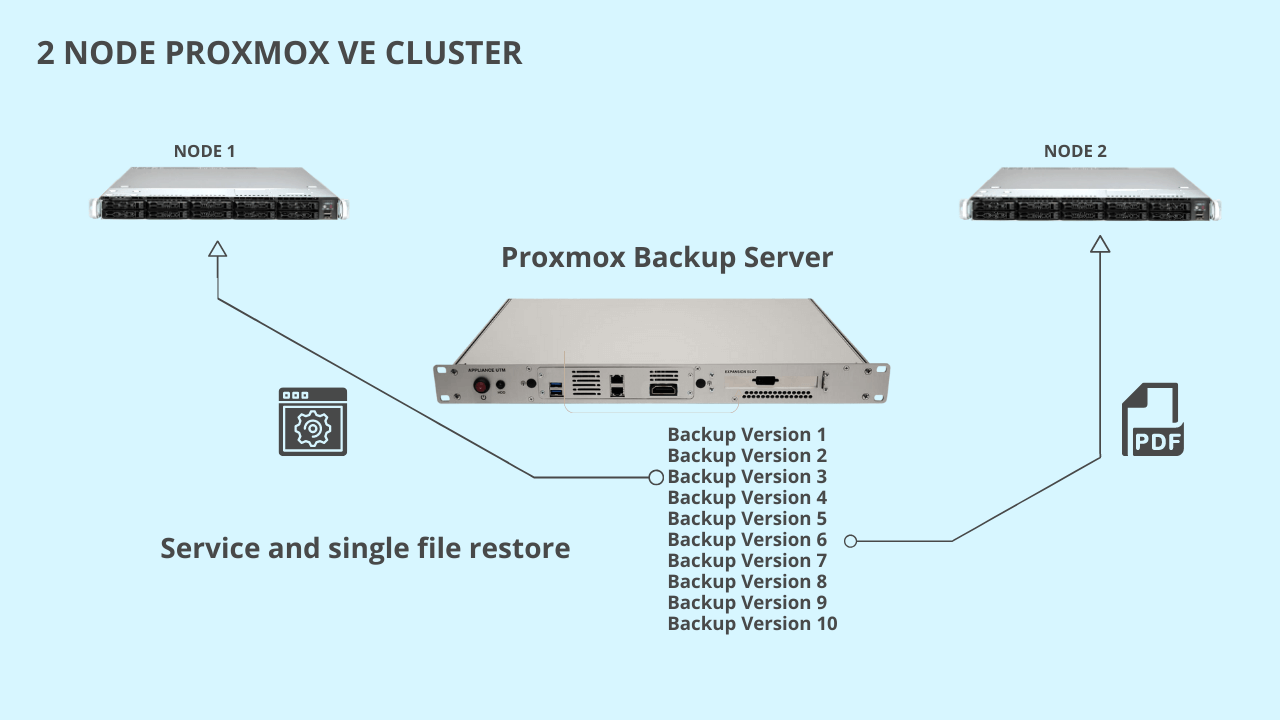 omware attack, it will be sufficient to restore one of the versions available on the PBS obtained thanks to the schedules set on the system.
omware attack, it will be sufficient to restore one of the versions available on the PBS obtained thanks to the schedules set on the system.
For example, if a CryptoLocker encrypts a virtual machine I can go back in time T-1 by selecting a version of previous versions.
While restoring the virtual machine with Proxmox Backup Server, you can start it up and thus already check whether that version is compromised or not, without waiting for the entire virtual machine to be restored.
5. No Single Point Of Failure
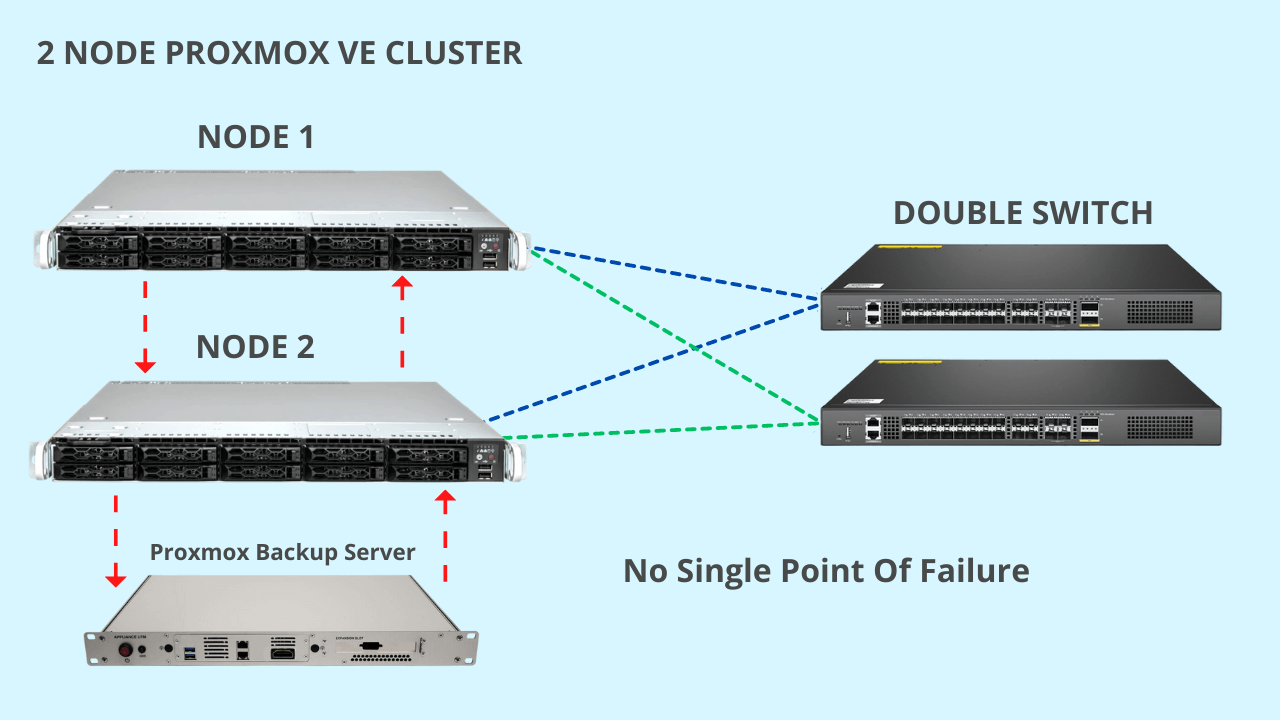
The 2 Node Proxmox VE Cluster has no Single Point of Failure because it is completely redundant.
By default we configure network cards, disks and networking in redundant mode, i.e. with double switch and multiple network cards for each service.
Also Proxmox Backup Server will have all redundant links.
Having a system without Single Point of Failure represents a great advantage for the operational continuity of a company.

