

In questo articolo spiegeremo i principi e le tematiche dell’infrastruttura iperconvergente, introducendo gli acronimi del settore per familiarizzare i lettori con l’iperconvergenza.
Esploreremo i concetti fondamentali, i principi di funzionamento e i vantaggi dell’iperconvergenza, nonché le sue applicazioni pratiche in diversi settori.
L’infrastrutura Iperconvergente
1. Introduzione
Nell’attuale era dell’informazione, le infrastrutture IT sono sotto pressione per soddisfare esigenze sempre più complesse e variabili.
L’iperconvergenza emerge come una soluzione strategica, unendo in un unico sistema integrato risorse di calcolo, storage e rete.
L’iperconvergenza è ad oggi, il sistema probabilmente più efficiente dal punto di vista prezzo/prestazioni presente sul panorama IT per la gestione di infrastrutture di dati e calcolo.
Durante il corso di questo articolo, esploreremo:
- I pilastri dell’iperconvergenza: storage, calcolo (RAM e CPU) e networking, e come ogni componente è virtualizzato e gestito in modo software-defined,
- Le tecnologie utilizzate nell’iperconvergenza: i cluster di storage distribuiti, i software di gestione centralizzata e le reti virtualizzate, e come queste soluzioni consentono di migliorare la flessibilità, la resilienza e le prestazioni complessive del sistema.
- Esploreremo un paio di casi di studio e applicazioni dell’iperconvergenza.
Getteiamo uno sguardo al futuro dell’iperconvergenza, esplorando le tendenze emergenti come l’integrazione con l’intelligenza artificiale e la machine learning.
Vediamo come queste sinergie possono aprire nuove opportunità e sfide per l’iperconvergenza, spingendo l’innovazione e consentendo alle aziende di affrontare le sfide del domani.
2. Terminologia usata nel mondo dell’iperconvergenza
Questin sono i reguenti termini e gli acronimi che sono comunemente usati nel mondo dell’iperconvergenza:
Nodo: In un sistema iperconvergente, un “nodo” è un singolo server fisico che fa parte di un cluster.
Ogni nodo contribuisce con risorse di calcolo (RAM e CPU), storage, rete e virtualizzazione, o anche una sola delle precedenti, rendendosi parte integrante dell’infrastruttura iperconvergente.
Cluster: In un sistema iperconvergente, un “cluster” è un gruppo di nodi connessi tra loro e gestiti come un’entità unica.
Questi nodi lavorano insieme per fornire una piattaforma integrata che offre risorse di calcolo, storage, rete e virtualizzazione in modo centralizzato.
HCI: “Hyper-Converged Infrastructure” (Infrastruttura Iperconvergente)
RTO: “Recovery Time Objective” (Obiettivo di Tempo di Recupero) è una metrica che definisce il periodo di tempo massimo accettabile entro il quale un’applicazione o un servizio deve essere ripristinato dopo un evento di guasto o interruzione.
In altre parole, l’RTO indica quanto velocemente un’applicazione o un servizio deve tornare completamente operativo dopo un’eventuale interruzione.
RPO: “Recovery Point Objective” è una metrica che indica l’intervallo di tempo massimo accettabile durante il quale i dati possono essere persi in caso di guasto o interruzione.
In altre parole, l’RPO definisce la quantità massima di dati che un’applicazione o un sistema può permettersi di perdere senza compromettere la continuità operativa e la coerenza dei dati.
TCO: “Total Cost of Ownership” (Costo Totale di Possesso) in un sistema iperconvergente. È una metrica che valuta tutti i costi associati all’implementazione, all’uso e alla manutenzione di un’infrastruttura iperconvergente durante l’intero ciclo di vita.
In particolare rappresenta l’insieme dei costi diretti e indiretti sostenuti da un’organizzazione per acquisire, configurare, utilizzare e mantenere l’infrastruttura iperconvergente durante il periodo di utilizzo.
Hypervisor: È il livello software che permette la virtualizzazione delle risorse fisiche in un nodo.
Si occupa di creare, avviare, sospendere e terminare le macchine virtuali o container e garantisce l’isolamento e l’efficienza delle risorse tra di esse e del nodo stesso. Tipicamente è installato sui nodi del Cluster.
Gli hypervisor più comuni in ambienti iperconvergenti sono VMware ESXi, Microsoft Hyper-V e KVM come Proxmox VE.
Scopri di più sul mondo dell’iperconvergenza
3. Concetti Fondamentali dell’Iperconvergenza
L’infrastruttura iperconvergente (HCI) integra in un’unica soluzione tutti gli elementi fondamentali di un data center, tra cui storage, calcolo (RAM e CPU), rete e virtualizzazione.
Possiamo dire che è l’insieme di server (detti nodi) e di switch che ne interconnettono le risorse per creare un’unica entità di elaborazione, ovvero un oggetto che è la somma di tutte le risorse dei nodi che chiameremo cluster.
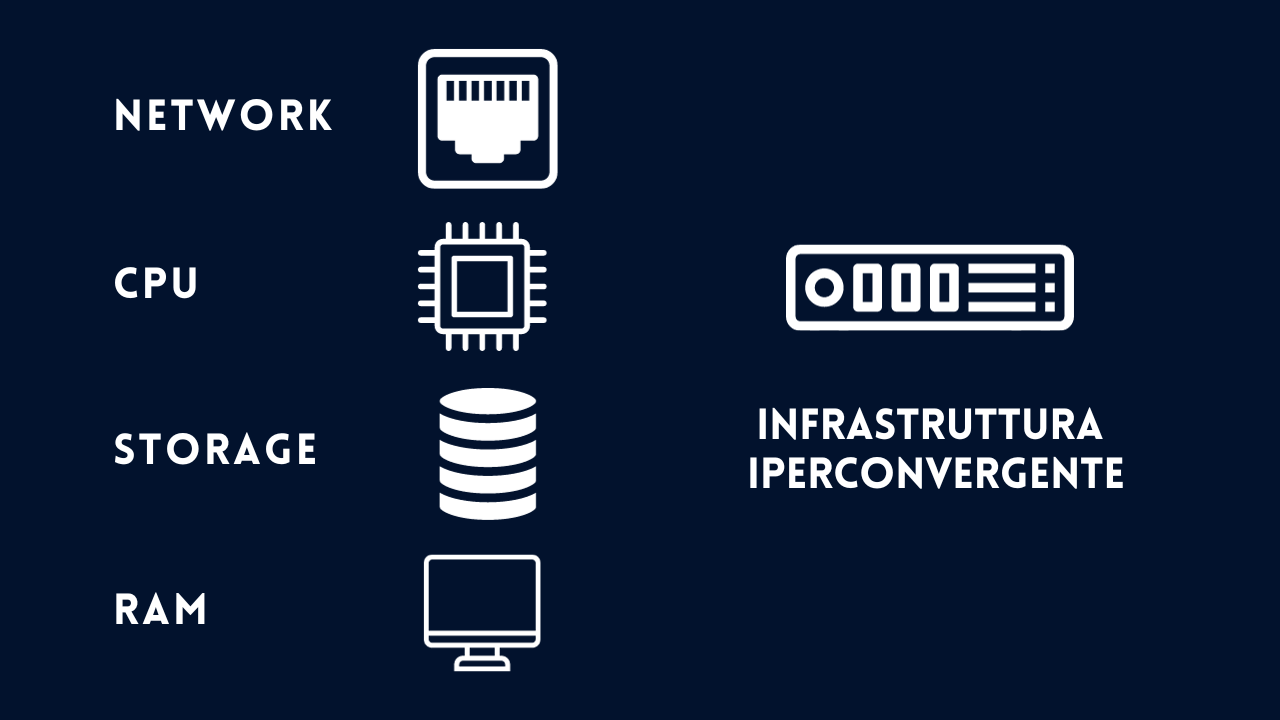
Immagina un diagramma con 4 blocchi (o pool) interconnessi: il blocco dello storage, il blocco del calcolo (RAM e CPU) e il blocco della rete. Ogni blocco rappresenta una componente fondamentale dell’iperconvergenza.
Nel blocco dello storage, si troveranno un insieme di dispositivi di storage come dischi rigidi e unità a stato solido.
Questi dispositivi verranno raggruppati in un pool condiviso e virtualizzato, creando un oggetto software-defined.
Ciò significa che la capacità di storage di tutti i dispositivi viene combinata e distribuita tra i nodi del cluster iperconvergente.
Nel blocco del calcolo, esisteranno una serie di nodi, ognuno dei quali combina risorse di calcolo come memoria RAM e CPU. Ogni nodo del cluster funge da unità di elaborazione, in grado di eseguire le applicazioni e i carichi di lavoro.
Grazie alla virtualizzazione, i carichi di lavoro possono essere distribuiti in modo dinamico tra i nodi, in base alle esigenze di prestazioni e di ridondanza. Ciò consente una gestione efficiente delle risorse e una maggiore agilità operativa.
Nel blocco della rete, essa è virtualizzata e gestita in modo Software-Defined Networking (SDN).
Ciò significa che la configurazione e il controllo della stessa avvengono attraverso software, anziché attraverso dispositivi di rete fisici tradizionali.
Le reti virtuali consentono una maggiore flessibilità e scalabilità, semplificando la gestione delle comunicazioni all’interno del cluster iperconvergente.
La virtualizzazione della rete consente anche un’implementazione più efficace dell’isolamento e della sicurezza delle reti, proteggendo i dati e le applicazioni.
Questi tre blocchi – storage, calcolo e rete – sono interconnessi e lavorano insieme per creare un’infrastruttura iperconvergente.
I dati vengono archiviati e gestiti nel pool di storage virtualizzato, i carichi di lavoro vengono eseguiti e distribuiti dinamicamente tra i nodi del cluster di calcolo, e le comunicazioni avvengono attraverso una rete virtualizzata.
Per semplificare al massimo il concetto facciamo un esempio con dei componenti comuni, ovvero dei server (nodi) e degli switch che li interconnettono:
Immaginiamo di avere 3 nodi identici, aventi ciascuno caratteristiche uguali, tra loro sono interconnessi con uno o più switch.
L’iperconvergenza, unita alla virtualizzazione, farà sì che il sistema risultante che chiameremo Cluster (o più genericamente piattaforma iperconvergente) sia la sommatoria di tutte le componenti dei nodi e degli switch.
Quindi un unico sistema (il cluster) metterà a disposizione delle applicazioni le risorse di calcolo, ovvero storage, RAM, CPU e rete.
Tutte le risorse saranno a disposizione delle applicazioni mediante l’astrazione di un layer software che approfondiremo di seguito.
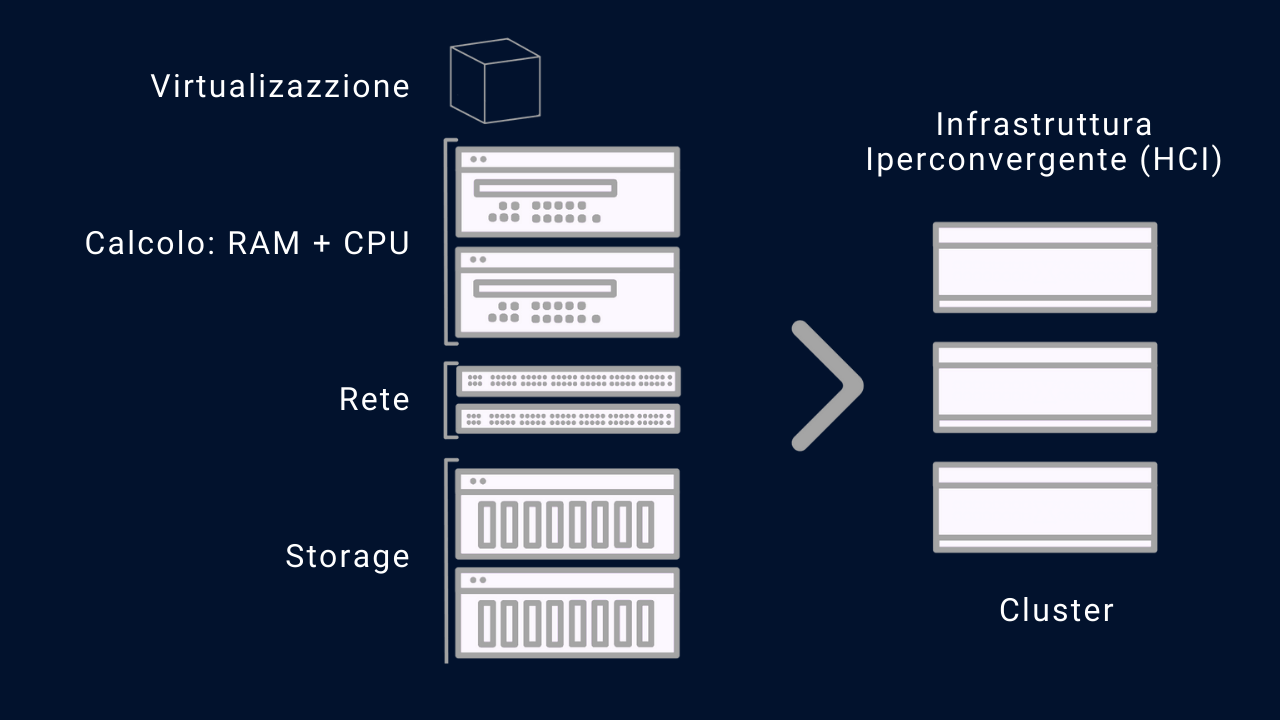
Cominciamo esaminando i tre pilastri principali dell’iperconvergenza ovvero storage, calcolo e rete.
3.1 Storage Iperconvergente
Lo storage iperconvergente integra lo storage di ciascun nodo all’interno della piattaforma iperconvergente, insieme alle risorse di calcolo e di rete.
In altre parole, tutte le risorse necessarie per gestire le applicazioni e i dati sono fornite da un singolo sistema, rendendo l’infrastruttura più semplice da gestire e scalare.
Le principali caratteristiche dello storage iperconvergente includono:
- Architettura Scale-Out: Lo storage iperconvergente utilizza un’architettura scale-out, in cui nuovi nodi possono essere facilmente aggiunti per aumentare la capacità di storage. Questo permette di scalare l’infrastruttura in modo modulare, senza la necessità di investire in grandi quantità di storage in anticipo.
- Ridondanza e Alta Disponibilità: Lo storage iperconvergente offre livelli di ridondanza per garantire la disponibilità dei dati anche in caso di guasti hardware.
I dati vengono replicati su più nodi all’interno del cluster, consentendo il recupero rapido e senza interruzioni in caso di problemi. - Gestione Centralizzata: Lo storage iperconvergente è gestito tramite un’interfaccia centralizzata che permette di controllare tutte le risorse di storage e di monitorare le prestazioni dell’infrastruttura.
Questo semplifica la gestione e riduce la complessità operativa. - Virtualizzazione dello Storage: Lo storage iperconvergente utilizza tecniche di virtualizzazione per creare uno strato astratto tra l’hardware di storage sottostante e le applicazioni.
Questo permette di fornire pool di storage virtuali che possono essere facilmente assegnati alle macchine virtuali o alle applicazioni che ne hanno bisogno. - Facilità di Gestione: Lo storage iperconvergente è progettato per essere facilmente gestibile anche da personale IT con meno esperienza.
L’automazione delle attività operative e la gestione centralizzata semplificano le operazioni quotidiane e riducono i tempi di configurazione e manutenzione. - Flessibilità nell’Utilizzo: Lo storage iperconvergente offre la possibilità di allocare dinamicamente le risorse di storage in base alle esigenze delle applicazioni.
Ciò consente di ottimizzare l’utilizzo dello spazio e di ridurre gli sprechi di risorse. - Prestazioni Ottimizzate: Lo storage iperconvergente è progettato per garantire alte prestazioni, grazie alla ridondanza dei dati e alla distribuzione intelligente delle operazioni di I/O su più nodi.
Ciò permette di supportare carichi di lavoro intensi senza degradare le prestazioni.
4. Networking Iperconvergente
Il networking è un elemento cruciale di un sistema iperconvergente, poiché è responsabile della connettività tra tutti i nodi dell’infrastruttura, consentendo la comunicazione e lo scambio di dati tra i diversi componenti.
La rete iperconvergente è progettata per supportare le esigenze di alta disponibilità, prestazioni elevate e scalabilità dell’infrastruttura.
Ecco come viene gestita la rete in un sistema iperconvergente:
- Networking Virtuale: Nella rete iperconvergente, il networking è spesso virtualizzato, esattamente come un semplice sistema di virtualizzazione a nodo singolo.Consente la creazione di reti virtuali isolate all’interno del cluster. Queste reti virtuali possono essere configurate per diversi scopi, come la separazione di carichi di lavoro, la gestione del traffico, o la segmentazione per motivi di sicurezza.
- Integrazione della Rete con i Nodi: La rete è strettamente integrata con i nodi dell’infrastruttura iperconvergente. Ogni nodo ha interfacce di rete multiple, che sono utilizzate in modo dedicato per:
- la comunicazione tra i nodi stessi
- la gestione dell’infrastruttura
- la connettività tra le risorse virtuali e il resto del mondo.
- Load Balancing: La rete iperconvergente utilizza tecniche di bilanciamento del carico per distribuire il traffico in modo uniforme tra i nodi.Questo permette di ottimizzare l’utilizzo delle risorse di rete e di evitare congestioni o punti di debolezza.
- Fault Tolerance: Per garantire l’alta disponibilità, la rete iperconvergente utilizza la ridondanza e la failover automatica.In caso di guasto di un nodo o di un’interfaccia di rete, il traffico viene automaticamente reindirizzato verso percorsi alternativi per evitare interruzioni del servizio.
- Gestione Centralizzata: La gestione della rete è centralizzata attraverso un’interfaccia di amministrazione unificata.Questo consente agli amministratori di monitorare le prestazioni di rete, configurare le reti virtuali e gestire le politiche di sicurezza in modo semplice e coerente.
- QoS (Quality of Service): La rete iperconvergente può implementare il QoS per garantire che le applicazioni e i carichi di lavoro critici ricevano la priorità sul traffico meno critico.Ciò permette di ottimizzare le prestazioni e garantire che le applicazioni importanti non siano degradate da altre attività di rete meno cruciali.
- Utilizzo del protocollo LACP (Link Aggregation Control Protocol) è ampiamente utilizzato nei sistemi iperconvergenti per fornire una maggiore disponibilità e capacità di larghezza di banda nella rete.LACP consente di aggregare fisicamente più porte di rete in un singolo canale logico, aumentando la capacità di trasferimento dei dati e fornendo ridondanza per garantire la continuità operativa.
5. Tecnologie e Strumenti nell’Iperconvergenza
Ci concentreremo ora sulle tecnologie e gli strumenti specifici utilizzati all’interno dell’iperconvergenza.
Esploreremo le principali componenti e le loro funzioni, offrendo una visione più dettagliata del funzionamento dell’iperconvergenza.
5.1 Software-Defined Storage
Uno degli aspetti chiave dell’iperconvergenza è il concetto di software-defined storage (SDS), che consente la virtualizzazione e la gestione centralizzata delle risorse di storage.
Attraverso il software-defined storage, i dispositivi di storage fisici vengono aggregati in un pool condiviso e gestiti in modo software.
Ciò consente di semplificare la gestione dello storage, fornire un’allocazione efficiente delle risorse e offrire funzionalità avanzate come la replica dei dati, la deduplicazione e la compressione.
5.2 Replica, Deduplicazione e Compressione
La replica dei dati, la deduplicazione e la compressione sono tecniche chiave utilizzate all’interno di un sistema iperconvergente per ottimizzare l’utilizzo dello storage, garantire l’affidabilità e l’alta disponibilità dei dati e migliorare le prestazioni dell’infrastruttura nel complesso.
Vediamole nel dettaglio:
5.3 Deduplicazione
La deduplicazione nei sistemi iperconvergenti mira ad eliminare dati duplicati all’interno dello storage.
Viene effettuata a livello di blocco o file e può essere implementata sia a livello locale (all’interno di ciascun nodo) che a livello globale (su tutto il cluster).
A livello di blocco, i dati vengono suddivisi in blocchi di dimensioni fisse.
La deduplicazione identifica blocchi di dati duplicati e mantiene una sola copia di ciascun blocco, riducendo lo spazio di storage richiesto per memorizzare dati ridondanti.
A livello di file, la deduplicazione si applica all’interno dei file stessi. I segmenti duplicati all’interno di un file vengono identificati e sostituiti con riferimenti ai segmenti unici, riducendo ulteriormente la quantità di dati memorizzati.
La deduplicazione aiuta a risparmiare spazio di storage e a ottimizzare l’utilizzo delle risorse dello storage, soprattutto in ambienti con molti dati replicati o con dati simili tra i nodi del cluster.

5.4 Replica dei dati
La replica dei dati nel contesto di un sistema iperconvergente implica la creazione di copie dei dati e la loro distribuzione su più nodi del cluster.
Questo processo può avvenire in modo sincrono o asincrono.
La replica sincrona richiede che tutti i nodi confermino l’avvenuta scrittura prima di restituire una conferma al client.
Questo assicura che i dati siano coerenti tra tutti i nodi, ma potrebbe introdurre una lieve latenza poiché l’operazione di scrittura deve essere riprodotta su tutti i nodi.
E’ a causa della replica sincrona che i nodi devono essere connessi tra di loro con una velocità pari se non superiore rispetto alla velocità dello storage.
In questo scenario si otterrà un RTO ed un RPO = 0. Questo è il caso tipico dei Cluster situati nello stesso sito geografico (o stesso datacenter) con la possibilità quindi di poter connettere i nodi con link molto veloci (almeno 25, 40, 100, 200, 400 Gbit/s).
Nella replica asincrona, i dati vengono copiati su nodi di destinazione in modo asincrono rispetto all’operazione di scrittura.
Questo può ridurre la latenza delle scritture, ma potrebbe comportare una minor coerenza dei dati in caso di guasti.
La replica dei dati garantisce che essi siano disponibili su più nodi, aumentando l’affidabilità del sistema e consentendo il failover in caso di guasti dei nodi.
Questo è il tipico caso in cui i nodi non sono situati nello stesso luogo geografico e per sincronizzarsi utilizzeranno una connessione tipicamente più lenta.
In questo caso avremo un RPO dipendente dalla velocità della connettività, tipicamente e statisticamente maggiore di 5 minuti.
5.5 Compressione
La compressione nell’iperconvergenza è una tecnica di ottimizzazione dello storage che riduce la dimensione dei dati utilizzando algoritmi di compressione che agiscono su blocchi di file.
La compressione a livello di blocco è una tecnica in cui i dati vengono suddivisi in blocchi di dimensioni fisse e ciascun blocco viene compresso singolarmente.
L’algoritmo di compressione analizza i dati all’interno di ciascun blocco e identifica i pattern e le ridondanze presenti.
Utilizzando tecniche come la codifica di lunghezza fissa, la codifica di lunghezza variabile o la codifica di Huffman, l’algoritmo riduce la dimensione dei dati, eliminando le ridondanze e ottimizzando la rappresentazione dei dati.
I dati possono essere compressi inline mentre vengono scritti nel sistema, oppure post-process dopo che sono stati scritti.
Per consentire prestazioni ottimali, la compressione inline e post-process viene determinata in modo intelligente in base a modelli di accesso sequenziale o casuale.
6. Il quorum nell’iperconvergenza
In questo capitolo vedremo quanti nodi deve avere un cluster, cosa è il quorum e cosa succede nel dettaglio quando si verifica un fault di uno o più nodi.
Il quorum nell’iperconvergenza è un concetto chiave per garantire la coerenza e l’affidabilità del sistema.
In un cluster iperconvergente, il quorum è definito come il numero minimo di nodi funzionanti richiesti per permettere al Cluster di prendere decisioni e gestire operazioni critiche.
Il quorum evita situazioni di partizione del cluster (Split Brain), in cui i nodi perdono la connettività tra loro e operano indipendentemente, mettendo a rischio la coerenza dei dati e la continuità del servizio.
Il meccanismo di voto basato su nodi è il più utilizzato. I nodi all’interno del cluster comunicano tra loro e partecipano a processi di voto per raggiungere una maggioranza e permettere al sistema di prendere decisioni consensuali al manifestarsi di eventi critici.
Ad esempio, al verificarsi di un fail, i nodi votano per determinare quale gruppo di nodi assumerà il ruolo di “master” e gestirà il servizio o il carico di lavoro precedentemente gestito dal nodo o nodi falliti.
L’heartbeat è un meccanismo mediante il quale i nodi di un cluster comunicano tra loro in modo regolare e periodico per segnalare la loro disponibilità e lo stato operativo.
In pratica, ogni nodo invia segnali di “vivo” (heartbeat) agli altri nodi del cluster, indicando che è attivo e funzionante.
Se un nodo smette di inviare gli “heartbeat” o non risponde, gli altri nodi possono rilevare un guasto e intraprendere azioni appropriate.
Ogni tecnologia iperconvergente integra un proprio sistema di calcolo del quorum all’interno del software di gestione del cluster.
Ad ogni nodo del cluster è assegnato un peso al voto che può dare. Tipicamente il peso del voto è 1, ma è possibile (anche se sconsigliato in quanto è una tecnica pericolosa) assegnare pesi differenti.
È fondamentale avere almeno 3 nodi nel cluster per diversi motivi:
Garantire la maggioranza: Con 3 nodi, anche se si verifica una perdita di connettività tra due di essi, rimangono comunque almeno 2 nodi funzionanti che costituiscono la maggioranza (il 66,66%).
Questo assicura che il cluster possa continuare a prendere decisioni consensuali e a mantenere la coerenza dei dati.

Con un numero dispari di nodi, si evitano situazioni di stallo in cui i nodi non riescono a raggiungere un consenso. Per questa ragione è preferibile avere cluster con un numero dispari di nodi.
Prevenire la divisione (o Split Brain) del cluster: Con solo due nodi, la perdita di connettività tra loro potrebbe portare a una divisione del cluster in due partizioni.
In questa situazione, entrambi i nodi non avrebbero la maggioranza, impedendo al cluster di prendere decisioni. Si verificherebbe così una situazione di stallo.
Per questo motivo non sono realizzabili Cluster a 2 nodi. Con almeno 3 nodi, è impossibile avere una partizione in cui entrambe le parti abbiano la maggioranza.
Affidabilità e tolleranza ai guasti: Avendo almeno 3 nodi, il cluster può sopportare la perdita di un nodo senza compromettere la disponibilità e la coerenza dei dati.
Inoltre, con 3 o più nodi, è possibile implementare strategie di replica dei dati e ridondanza, garantendo un ambiente resiliente.
6.1 Utilizzo di nodi testimone
Il nodo testimone ha il compito di fornire un punto di “voto” aggiuntivo in decisioni che riguardano il quorum, specialmente in configurazioni che hanno un numero pari di nodi.
In caso di perdita di connettività tra i nodi del cluster, il nodo testimone aiuta a stabilire quale sottoinsieme di nodi detiene la maggioranza e, quindi, può operare come cluster.
Ad esempio, in un cluster di 2 nodi (una configurazione tipicamente problematica per la gestione del quorum), l’aggiunta di un nodo testimone fornisce un terzo punto di “voto”, permettendo di evitare situazioni di stallo.
Se uno dei nodi principali va offline o perde la connettività, il nodo testimone fornisce il voto decisivo che permette all’altro nodo di continuare a funzionare, assumendo che esso stesso sia in uno stato operativo e connesso al nodo testimone.
Si differenzia con gli altri nodi in quanto non dispone di risorse di calcolo, storage e networking in grado di eseguire VM o CT, ma solo di fornire il voto indispensabile a garantire il meccanismo del quorum.
Si noti che a seconda del vendor che lo implementa può assumere nomi differenti. In VmWare viene chiamato nodo witness, mentre in Proxmox viene chiamato “Quorum Disk” o “QDevice”.
Nel caso in cui il quorum non funzionasse correttamente in concomitanza ad una situazione di fault, potrebbe verificarsi una situazione detta Split Brain.
Questa situazione è piuttosto remota, data la maturità della tecnologia, tuttavia è interessante analizzare questa situazione tecnicamente per comprendere in profondità alcuni importanti meccanismi.
6.2 Split Brain del Cluster
Seppur sia molto difficile che si verifichi in quanto ogni Cluster Maker è molto attento a non ricadere in questa situazione, qualora il meccanismo del quorum non funzionasse correttamente in caso di fault potrebbe verificarsi uno split brain.
Lo “split brain” è una situazione indesiderata che può verificarsi in un cluster iperconvergente quando i nodi perdono la connettività tra loro, ma continuano a operare indipendentemente come se fossero due cluster separati.
Questa condizione può verificarsi a causa di problemi di rete o di guasti nei sistemi di comunicazione tra i nodi.
6.3 Descrizione tecnica dello split brain in un cluster iperconvergente
In un cluster iperconvergente, i nodi lavorano insieme per garantire la coerenza dei dati e la gestione condivisa delle risorse.
Comunicano tra loro attraverso una rete interna per prendere decisioni consensuali, distribuire i carichi di lavoro e garantire l’affidabilità del sistema.
Quando si verifica uno split brain, alcuni nodi del cluster perdono la connettività con gli altri nodi, ma continuano a essere operativi.
Questo può accadere, ad esempio, a causa di un problema di rete che isola temporaneamente alcuni nodi dal resto del cluster.
I nodi isolati, anche senza maggioranza (no quorum) continuano a ricevere richieste di calcolo e accesso ai dati (di fatto continuano ad eseguire VM e CT), ma non sono in grado di comunicare con gli altri nodi per prendere decisioni condivise.
Facciamo un esempio: immaginiamo un cluster iperconvergente composto da quattro nodi.
Normalmente, i nodi comunicano tra di loro e condividono dati e informazioni per fornire servizi di calcolo, storage e rete in modo coerente.

Cluster 4 nodi. No Quorum.
A causa di un problema di rete, la comunicazione tra due coppie di nodi si interrompe.
Ad esempio, i nodi 1 e 2 non riescono a comunicare con i nodi 3 e 4. In questa situazione, i nodi 1 e 2 possono ancora vedere l’uno l’altro e considerarsi “attivi” insieme, mentre i nodi 3 e 4 si considerano anch’essi attivi l’uno con l’altro.
Questo crea due gruppi di nodi “attivi” che si considerano il centro del cluster, ognuno pensando di avere il controllo.
Si noti che in questa situazione, essendo pari il numero di nodi, in una situazione normale, i 2 “pezzi” del cluster dovrebbero decidere di mettersi in una situazione di fencing e bloccare l’erogazione di tutti i servizi per evitare i seguenti problemi:
Decisioni divergenti: I nodi isolati possono prendere decisioni divergenti riguardo la gestione dei carichi di lavoro o dei dati, causando gravi inconsistenze e perdita di coerenza all’interno del cluster.
Duplicazione dei dati: Se i nodi isolati continuano a scrivere sui dati, potrebbe verificarsi una duplicazione delle informazioni tra i nodi del cluster. Questo può portare a conflitti di dati e perdita di integrità.
Guasti a cascata: Se i nodi isolati si riconnettono al cluster in seguito, la riunificazione dei dati potrebbe causare guasti a cascata, con conseguente instabilità e problemi di prestazioni.
6.4 Comportamento normale di un Cluster iperconvergente in una situazione di fault
Esistono svariati scenari che si possono verificare. Iniziamo analizzando il caso dell’esempio precedente ed il comportamento corretto:
Abbiamo un Cluster composto da 4 nodi, in cui la comunicazione si interrompe e 2 di questi vengono isolati.
Le 2 parti del Cluster si metteranno così in una situazione di fencing ovvero una situazione di sicurezza utilizzata per garantire la consistenza e l’integrità del cluster in presenza di un guasto o di un nodo (o gruppo di nodi) inattivo.
Quando un nodo in un cluster iperconvergente diventa inattivo o smette di rispondere, potrebbe sorgere il rischio di “brain-split”.
Per evitare questo problema, il fencing è utilizzato per “isolare” il nodo inattivo o problematico, interrompendo la sua connettività o alimentazione in modo che non possa né interagire con gli altri nodi del cluster.
Nel caso in cui il nodo “isolato” non riuscisse più a raggiungere il resto del cluster ma risultasse attivo e funzionante, sarebbe lui stesso a mettersi in fencing.
Ciò assicura che solo i nodi “sani” e “attivi” continuino a operare nel cluster continuando ad erogare servizi.
Nel nostro esempio a 4 nodi, il comportamento corretto sarebbe che entrambe le due parti del cluster si mettano nello stato di fencing. Ovvero tutto il cluster dovrebbe smettere di funzionare.
Adesso che abbiamo definito chi e come vengono prese le decisioni all’interno di un cluster vediamo cosa succede ai dati, VM e CT presenti sui nodi del Cluster.
6.5 Regole di HA
le regole di HA (High Availability) in un cluster iperconvergente mirano a garantire la disponibilità continua dei servizi, attivando il failover quando necessario.
Vengono configurate con l’obiettivo di massimizzare la resilienza e ridurre al minimo il downtime dei carichi di lavoro, consentendo al cluster di fornire alta affidabilità per le applicazioni ospitate.
Esse rappresentano le istruzioni che il Cluster seguirà al verificarsi di eventi come il fault di un nodo.
Tipicamente si occupano di:
- Attivazione del failover: Dopo aver rilevato un guasto o un problema, le regole di HA attivano il failover, che è il processo di ripristino delle risorse e dei servizi su un altro nodo funzionante.Ad esempio, le macchine virtuali o i container possono essere migrati automaticamente su un nodo sano e funzionante del cluster.
- Ridistribuzione del carico: Se il failover coinvolge il movimento delle risorse, le regole di HA assicurano che il carico di lavoro venga distribuito in modo bilanciato tra i nodi disponibili.Ciò aiuta a evitare il sovraccarico dei nodi e a garantire prestazioni ottimali.
- Garanzia di quorum: prima di prendere decisioni critiche come, per esempio, la migrazione delle risorse, viene verificato il “quorum” del cluster.
- Gestione delle priorità: Le regole di HA possono anche gestire le priorità delle risorse e dei servizi per garantire che le risorse più critiche vengano ripristinate prima in caso di failover.
È utile notare che le politiche di failover possono essere estremamente personalizzate.
Ad esempio, in alcune implementazioni, è possibile impostare livelli di priorità per le macchine virtuali o i servizi, in modo che in caso di guasto, i servizi più critici vengano migrati per primi.
Scopri di più sul mondo dell’iperconvergenza
7. Creazione di un Cluster Distribuito Geograficamente: Requisiti e Considerazioni
L’implementazione di un cluster distribuito geograficamente è una strategia di ridondanza avanzata che consente di aumentare l’affidabilità e la continuità operativa di un’infrastruttura IT.
Si realizza dislocando nodi in diverse ubicazioni fisiche, spesso in città o regioni diverse.
Questa configurazione è ideale per garantire la resilienza e la disponibilità continua dei servizi, riducendo il rischio di perdita di dati e di interruzioni dovute a eventi catastrofici locali.
7.1 Numero Minimo di Nodi
Un cluster geograficamente distribuito richiede un numero minimo di nodi e di siti per garantire la funzionalità e la resilienza.
Il numero esatto dipende dalla complessità dell’ambiente e dalle politiche di ripristino aziendali, ma di solito è necessario un minimo di tre nodi distribuiti tra almeno tre sedi diverse.
Questo permette di implementare una maggioranza di nodi in caso di divisione geografica.
Come per il numero minimo di nodi, anche le sedi che ospiteranno i nodi dovranno essere di numero dispari maggiore di 2.
Valgono, dunque, le stesse considerazioni fatte nel capitolo dove è stato affrontato l’argomento del quorum.
7.2 Connettività Affidabile
Una connettività di rete affidabile tra i nodi è essenziale. Questa connessione dovrà essere ottenuta tramite linee Internet dedicate, collegamenti VPN sicuri o reti MPLS (Multiprotocol Label Switching).
La bassa latenza e la larghezza di banda adeguata sono fondamentali per garantire prestazioni ottimali e tempi di ripristino rapidi.
7.3 Il networking tra i nodi
Come per una soluzione implementata localmente, anche un cluster geograficamente distribuito dovrà avere i nodi interconnessi l’uno all’altro.
Questo comporterà che ogni sede dovrà essere connessa alle altre mediante connessioni a bassa latenza.
È dunque facile notare che al crescere del numero delle sedi, le connessioni tra di esse saranno sempre più numerose.
Di seguito uno schema esemplificativo dove i cerchi rappresentano le sedi e i segmenti rappresentano le connessioni tra le sedi.
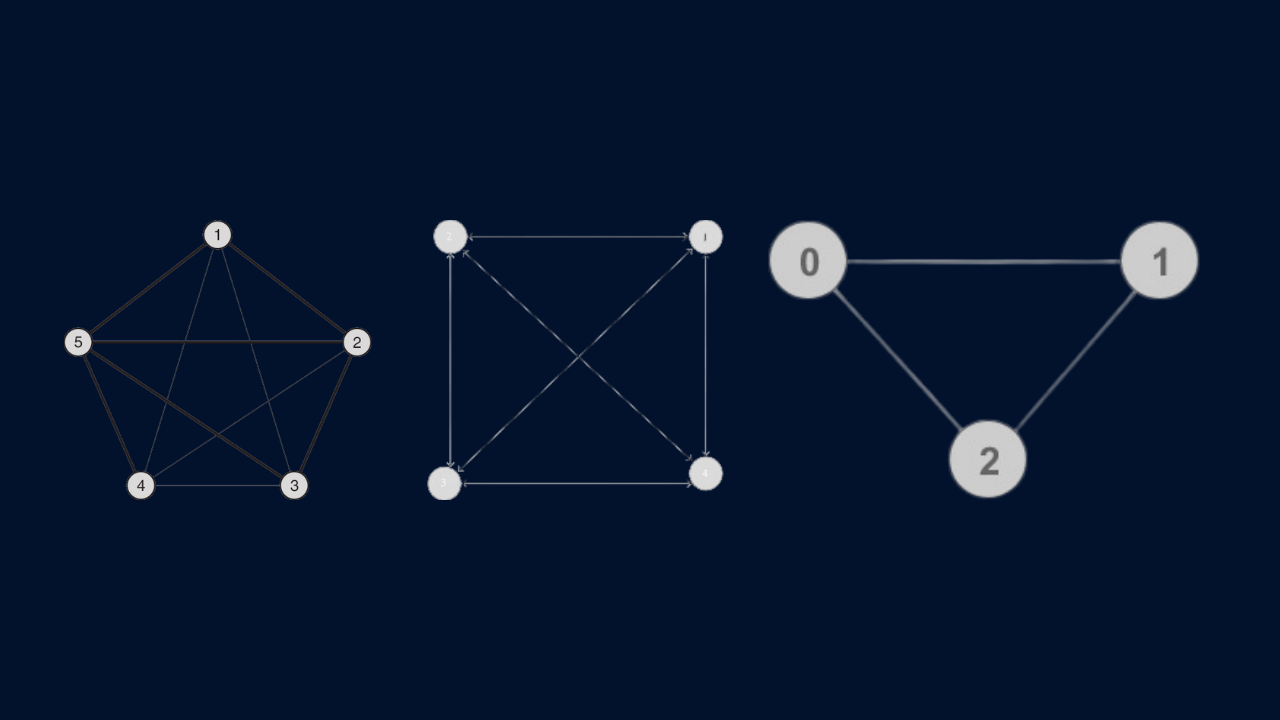
Come si può notare il numero di connessioni aumenterà esponenzialmente con l’aumentare del numero delle sedi.
Per il calcolo del numero di connessioni tra sedi, si sta effettivamente riferendo a una formula combinazionale. Il numero di connessioni è dato dalla formula:
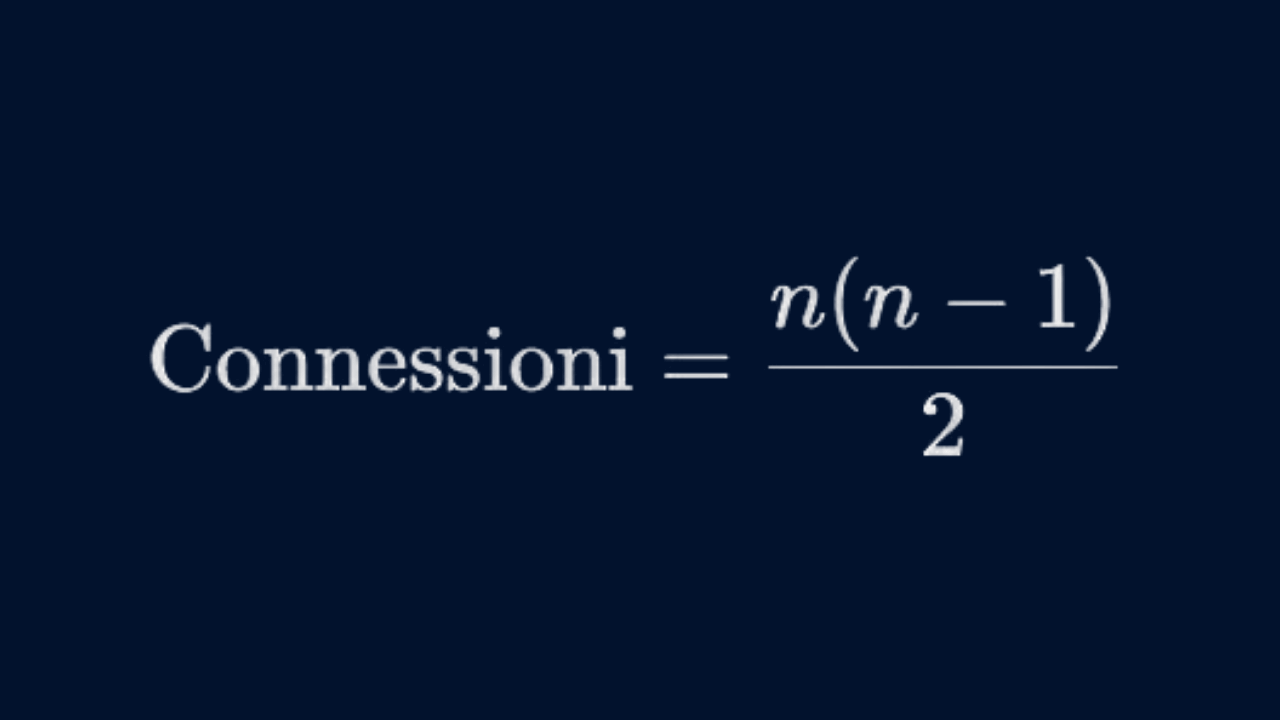
Dove n è il numero di sedi.
| N. di sedi | Connessione tra le sedi |
|---|---|
| 3 | 3 |
| 4 | 6 |
| 5 | 10 |
La connessione tra le sedi può rappresentare un limite all’implementazione di questa tecnologia che prevede la distribuzione geografica delle risorse, per via della difficoltà ad ottenere un’ampiezza di banda adeguata e basse latenze.
Per i cluster geograficamente distribuiti, distribuiti su molte sedi, si dovrebbe considerare l’uso di Global Load Balancers (GLB) per distribuire il traffico tra diverse regioni.
Questo può fornire un ulteriore livello di resilienza, distribuendo il carico non solo tra i nodi in una singola posizione, ma tra diverse posizioni geografiche.
7.4 Tipi di Replica tra i nodi delle sedi
La replica dei dati tra i nodi delle varie sedi è il cuore di un cluster distribuito.
Ecco alcuni approcci comuni di cui abbiamo già approfondito gli aspetti nel capitolo dedicato precedente.
7.5 Replica Sincrona
La replica sincrona implica che i dati vengano scritti su tutti i nodi contemporaneamente prima che una conferma venga inviata al nodo mittente.
Questo garantisce che i dati siano coerenti tra i nodi, ma può aumentare la latenza delle operazioni di scrittura a causa della necessità di attendere la conferma da tutti i nodi.
Tipicamente questa tecnologia è ad oggi difficilmente (praticamente impossibile) implementabile per via delle tecnologie di telecomunicazione che al momento della stesura di questo testo non sono ancora mature o economicamente accessibili.
7.6 Replica Asincrona
Nel caso della replica asincrona, i dati vengono scritti su un nodo e successivamente replicati in altri nodi.
Questo riduce la latenza delle operazioni di scrittura, ma potrebbe comportare la perdita di alcuni dati in caso di guasto improvviso.
Questa è la tecnologia maggiormente utilizzata.
Nel contesto della replica dei dati, è anche importante conoscere il concetto di “latency budget”. Si tratta del massimo ritardo che si può tollerare per la replicazione dei dati tra i nodi, soprattutto in un ambiente geograficamente distribuito.
Questo sarà un fattore limitante nella scelta tra replica sincrona e asincrona.
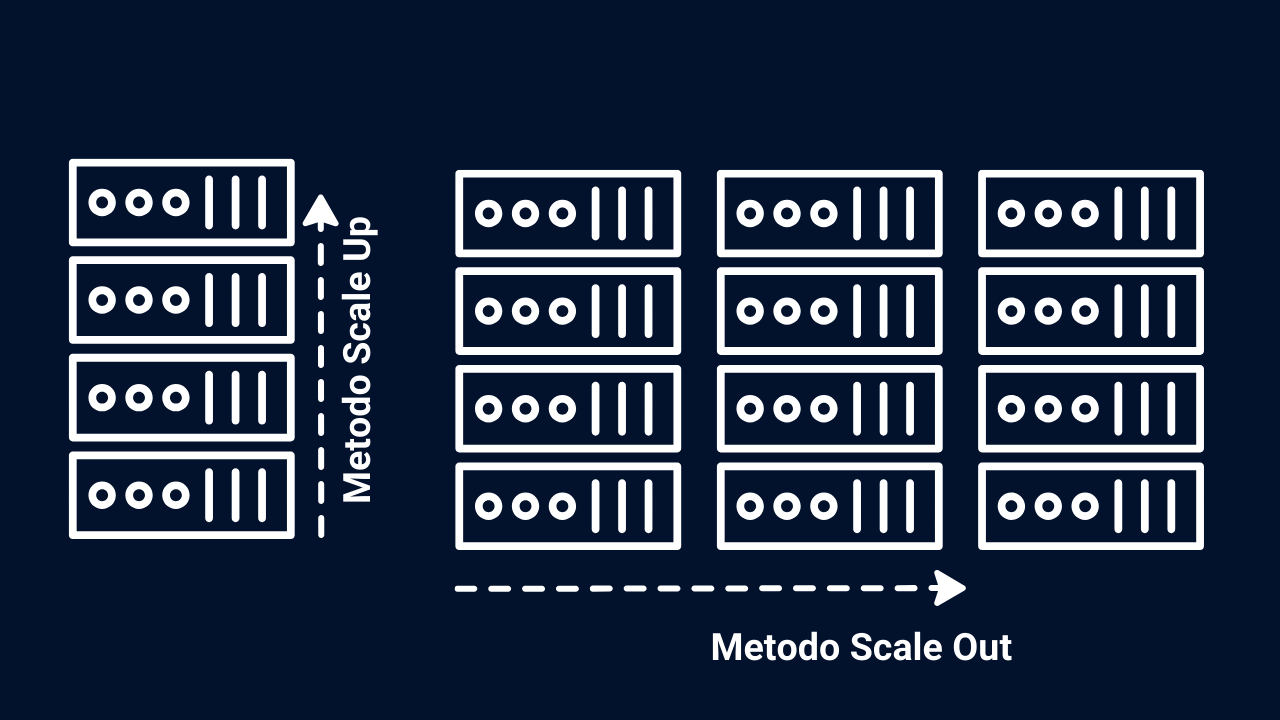
8. Come si espande un sistema iperconvergente
- Metodo dello Scale-Out: sia per lo storage che per il calcolo, lo scale-out consente di aggiungere nuovi nodi per aumentare la capacità di calcolo dell’infrastruttura.Questo permette di espandere l’elaborazione delle risorse in modo modulare e flessibile, in linea con le esigenze delle applicazioni e dei carichi di lavoro.
- Metodo Scale-up: nell’architettura scale-in, i singoli nodi o appliance vengono aggiunti per espandere l’infrastruttura, ma invece di aggiungere nodi individuali come nell’architettura scale-out, si aumenta la capacità aggiungendo risorse ai nodi esistenti.
9. Il Futuro dell’Iperconvergenza: Intelligenza Artificiale e Machine Learning
L’intelligenza artificiale (AI) e il machine learning (ML) sono tecnologie emergenti che hanno il potenziale di rivoluzionare diversi aspetti dell’IT, inclusi i sistemi iperconvergenti.
Queste tecnologie possono essere integrate in vari livelli del stack iperconvergente, dal monitoraggio del sistema all’ottimizzazione delle risorse e alla sicurezza.
9.1 Ottimizzazione delle Risorse
Gli algoritmi di machine learning possono essere utilizzati per analizzare i pattern di utilizzo delle risorse (CPU, memoria, storage, rete) in tempo reale.
Ciò permette al sistema di fare predizioni accurate sui requisiti futuri e di adattare di conseguenza la distribuzione delle risorse.
Ad esempio, il machine learning può prevedere un aumento del carico di lavoro e avviare preventivamente l’allocazione di risorse aggiuntive, migliorando così la performance e l’efficienza.
9.2 Manutenzione Predittiva
L’AI può migliorare significativamente le capacità di monitoraggio dei sistemi iperconvergenti.
Con l’uso di algoritmi di ML per l’analisi dei dati, è possibile identificare anomalie o pattern che potrebbero indicare un problema imminente, consentendo una manutenzione predittiva.
Questo riduce i tempi di inattività e migliora la resilienza del sistema.
9.3 Sicurezza e Conformità
Gli algoritmi di AI e ML possono essere utilizzati per migliorare le funzionalità di sicurezza, identificando in modo proattivo possibili vulnerabilità o attacchi in tempo reale.
Ciò potrebbe includere il riconoscimento di pattern di traffico di rete sospetti o variazioni anomale nel comportamento del sistema che potrebbero indicare una compromissione della sicurezza.
9.4 Automazione e Orchestrazione
L’intelligenza artificiale può anche essere integrata nei processi di automazione e orchestrazione, permettendo al sistema di prendere decisioni più intelligenti riguardo al posizionamento dei carichi di lavoro, al bilanciamento del carico e alla gestione dei guasti.
Ad esempio, un algoritmo di ML potrebbe analizzare i dati storici e i parametri di esecuzione per determinare il miglior nodo su cui eseguire una nuova istanza di una macchina virtuale.
10. Esempio di Calcolo del TCO con Costi di Licenza Annuali Ridotti e Dettagli Hardware
Il TCO (Total Cost of Ownership, o Costo Totale di Proprietà) in un cluster iperconvergente è una misura finanziaria completa che prende in considerazione tutti i costi diretti e indiretti associati all’acquisizione, implementazione, manutenzione e gestione di un’infrastruttura iperconvergente.
Questo indicatore è estremamente utile per valutare l’efficacia economica di una soluzione iperconvergente rispetto ad altre architetture, come quelle basate su infrastrutture separate per calcolo, storage e networking.
Componenti del TCO in un cluster iperconvergente
Costi Iniziali (Capex)
Acquisto di hardware: server, storage, e componenti di networking.
Software e licenze: inclusi i sistemi operativi, hypervisor, e software di gestione.
Installazione e configurazione: costi legati all’installazione iniziale e alla configurazione del cluster.
Costi Operativi (Opex)
Energia elettrica e raffreddamento: costi continui per mantenere il sistema in funzione.
Manutenzione e supporto: contratti di manutenzione, aggiornamenti, e costi di supporto tecnico.
Gestione e amministrazione: costi del personale per la gestione quotidiana del sistema.
Costi Software
Licenze: costi annuali o pluriennali per il software di virtualizzazione e gestione del cluster.
Aggiornamenti: costi per aggiornamenti software e eventuali nuove licenze.
Costi Indiretti
Downtime: costi associati a eventuali periodi di inattività non pianificati.
Formazione: costi per formare il personale tecnico sulla nuova infrastruttura.
11. Esempio di calcolo del TCO
Consideriamo un cluster iperconvergente con le seguenti specifiche hardware e costi:
Caratteristiche Hardware per Nodo:
- CPU: 16 core
- RAM: 128 GB
- Storage: 4 TB SSD
- Costo dell’hardware per nodo (incluso costo del networking): €10.000
- Numero di nodi: 5
- Costo della licenza software: €105 per anno per nodo
- Costi annuali di manutenzione e supporto: €1.000 per nodo
- Costi annuali di energia e raffreddamento: €500 per nodo
- Vita utile stimata del cluster: 5 anni
Calcoliamo prima il Costo di Acquisizione:
- Costo di Acquisizione=Costo dell’hardware per nodo×Numero di nodi
- Costo di Acquisizione=€10,000×5
- Costo di Acquisizione=€50,000
Successivamente, calcoliamo i Costi Operativi annuali per nodo:
Costi Operativi annui per nodo=Costi di manutenzione e supporto per nodo + Costi di energia e raffreddamento per nodo + Costo della licenza software per anno per nodo
- Costi Operativi annui per nodo=€1,000+€500+€105
- Costi Operativi annui per nodo=€1,605
Ora, calcoliamo i Costi Operativi totali per la vita utile del cluster:
Costi Operativi totali=Costi Operativi annui per nodo × Numero di nodi × Vita utile
- Costi Operativi totali=€1,605×5×5
- Costi Operativi totali=€40,125
Infine, possiamo calcolare il TCO:
TCO=Costo di Acquisizione + Costi Operativi totali
- TCO=€50,000+€40,125
- TCO=€90,125
Per determinare il costo mensile della soluzione per la sua vita utile, possiamo dividere il TCO per il numero totale di mesi

In questo esempio aggiornato, il TCO per il cluster iperconvergente sarebbe di €90,125 per un periodo di 5 anni, con un costo mensile di €1,502.08.
Il costo delle licenze software è stato paragonato ad una licenza Proxmox VE.
12. Casi pratici, esempi e curiosità sui temi dell’iperconvergenza
In questo capitolo vedremo qualche caso pratico e approfondirò alcuni quesiti che spesso ricorrono nelle trattazioni legate all’iperconvergenza.
12.1 Cluster Geolocalizzato su 2 sedi: è possibile?
Come ampiamente descritto in precedenza, nelle trattazioni relative all’iperconvergenza, tutti i numeri pari e minori di 3 non sono ben visti da questa tecnologia.
Tuttavia, nel panorama aziendale italiano, dove la piccola e media azienda rappresenta il 96% della forza lavoro nazionale, occorre provare a fare uno sforzo per fornire una soluzione al problema.
Questo è il caso tipico di una piccola/media azienda interessata ad una ridondanza dei dati e delle risorse su siti differenti e geograficamente distanti.
Una possibile soluzione:
La soluzione consiste nell’uso di 2 Cluster iperconvergenti installati uno per sede.
Tra le 2 sedi sarà necessario implementare una VPN e impostare una replica asincrona tra i due cluster delle risorse (VM e CT).
In questo modo si otterrà una soluzione percorribile ed economicamente sostenibile.
12.2 Esiste l’iperconvergenza per un singolo nodo?
Leggendo i manuali dei vari framework che implementano l’iperconvergenza si possono apprezzare le varie trattazioni che approfondiscono la tecnologia anche a basso livello.
Per comprendere come possa esistere un solo nodo iperconvergente, bisogna pensare all’iperconvergeza come una particolare tecnologia e non come una soluzione a una specifica problematica.
Per esempio, è possibile realizzare un nodo singolo applicando l’iperconvergenza ai singoli dischi fisici all’interno del singolo nodo stesso.
I singoli dischi convergeranno mediante il bus di sistema (e non mediate il networking) in un unico storage software-defined come in un sistema su più nodi.
A cosa potrebbe servire un sistema del genere?
L’unica risposta che mi viene in mente è un puro esercizio di stile che non risolve nessun nuovo problema in quanto il sistema così ottenuto non avrebbe nessun vantaggio rispetto a sistemi già ampiamente in uso da decenni.
12.3 I nodi di un cluster devono essere tutti uguali?
Una delle domande più comuni nella progettazione di un cluster, soprattutto in un contesto iperconvergente, riguarda l’omogeneità dei nodi.
In altre parole, i nodi all’interno del cluster devono avere le stesse specifiche hardware e software?
La risposta a questa domanda è complessa e dipende da vari fattori come l’applicazione specifica, il livello di tolleranza ai guasti, le esigenze di performance e la complessità nella gestione.
Vantaggi dell’Omogeneità
- Semplificazione della Gestione: Un ambiente omogeneo è più facile da gestire.
Le procedure di manutenzione, aggiornamento e risoluzione dei problemi diventano più semplici quando tutti i nodi sono identici. - Bilanciamento del Carico: In un ambiente omogeneo, il bilanciamento del carico tra i nodi è più prevedibile.
Questo è particolarmente utile per le applicazioni che richiedono una distribuzione uniforme delle risorse. - Migliore Utilizzo delle Risorse: Con nodi identici, è più facile ottimizzare l’utilizzo delle risorse, poiché ogni nodo è capace delle stesse performance.
Svantaggi dell’Omogeneità
- Costi: Avere nodi con specifiche elevate può essere costoso, specialmente se alcune applicazioni o servizi non richiedono alti livelli di risorse.
- Flessibilità Limitata: Un ambiente omogeneo potrebbe non essere adatto per gestire carichi di lavoro diversificati che hanno requisiti molto specifici in termini di calcolo, memoria o storage.
Vantaggi dell’Eterogeneità
- Flessibilità: Un ambiente eterogeneo consente di adattare ogni nodo alle esigenze specifiche di certi carichi di lavoro. Ad esempio, alcuni nodi potrebbero essere ottimizzati per il calcolo mentre altri per lo storage.
- Ottimizzazione dei Costi: È possibile utilizzare hardware meno costoso per i nodi che non necessitano di alte prestazioni, riducendo così il costo totale del cluster.
Svantaggi dell’Eterogeneità
- Complessità nella Gestione: L’eterogeneità introduce una maggiore complessità nella gestione del cluster. Ad esempio, la politica di aggiornamenti e patch dovrà tenere conto delle diverse specifiche hardware e software.
- Bilanciamento del Carico: In un ambiente eterogeneo, il bilanciamento del carico diventa più complesso. È necessario avere un sistema intelligente che sappia come distribuire i carichi di lavoro in base alle capacità di ciascun nodo.
13. Considerazioni Finali
In generale, non esiste una risposta definitiva se i nodi in un cluster devono essere omogenei o eterogenei; tutto dipende dai requisiti specifici del sistema e delle applicazioni che dovranno essere eseguite.
Tuttavia, è fondamentale effettuare una valutazione accurata delle necessità prima di prendere una decisione, considerando sia i vantaggi sia gli svantaggi di ciascun approccio.
Per esempio, in un contesto “piccolo”, ovvero un cluster classico a 3 nodi, normalmente, non ha senso utilizzare nodi con hardware differente.


