
Capitoli
- Introduzione
- Terminologia e Concetti Fondamentali
- Tecnologie e Strumenti nell’Iperconvergenza
- Funzionamento del Cluster nell’iperconvergenza
- Creazione di un Cluster Distribuito Geograficamente Requisiti e Considerazioni
- Come si espande un sistema iperconvergente
- Esempio di Calcolo del TCO
- Casi pratici, esempi e curiosità sui temi dell’iperconvergenza
- Note finali
2. Terminologia e Concetti Fondamentali
In questo capitolo riporterò i termini e gli acronimi che sono comunemente usati nel mondo dell’iperconvergenza.
Nodo: In un sistema iperconvergente, un “nodo” è un singolo server fisico che fa parte di un cluster. Ogni nodo contribuisce con risorse di calcolo (RAM e CPU), storage, rete e virtualizzazione, o anche una sola delle precedenti, rendendosi parte integrante dell’infrastruttura iperconvergente.
Cluster: In un sistema iperconvergente, un “cluster” è un gruppo di nodi connessi tra loro e gestiti come un’entità unica. Questi nodi lavorano insieme per fornire una piattaforma integrata che offre risorse di calcolo, storage, rete e virtualizzazione in modo centralizzato.
HCI: “Hyper-Converged Infrastructure” (Infrastruttura Iperconvergente)
RTO: “Recovery Time Objective” (Obiettivo di Tempo di Recupero) è una metrica che definisce il periodo di tempo massimo accettabile entro il quale un’applicazione o un servizio deve essere ripristinato dopo un evento di guasto o interruzione. In altre parole, l’RTO indica quanto velocemente un’applicazione o un servizio deve tornare completamente operativo dopo un’eventuale interruzione.
RPO: “Recovery Point Objective” è una metrica che indica l’intervallo di tempo massimo accettabile durante il quale i dati possono essere persi in caso di guasto o interruzione. In altre parole, l’RPO definisce la quantità massima di dati che un’applicazione o un sistema può permettersi di perdere senza compromettere la continuità operativa e la coerenza dei dati.
TCO: “Total Cost of Ownership” (Costo Totale di Possesso) in un sistema iperconvergente. È una metrica che valuta tutti i costi associati all’implementazione, all’uso e alla manutenzione di un’infrastruttura iperconvergente durante l’intero ciclo di vita. In particolare rappresenta l’insieme dei costi diretti e indiretti sostenuti da un’organizzazione per acquisire, configurare, utilizzare e mantenere l’infrastruttura iperconvergente durante il periodo di utilizzo.
Hypervisor: È il livello software che permette la virtualizzazione delle risorse fisiche in un nodo. Si occupa di creare, avviare, sospendere e terminare le macchine virtuali o container e garantisce l’isolamento e l’efficienza delle risorse tra di esse e del nodo stesso. Tipicamente è installato sui nodi del Cluster. Gli hypervisor più comuni in ambienti iperconvergenti sono VMware ESXi, Microsoft Hyper-V e KVM come Proxmox.
3. Concetti Fondamentali dell’Iperconvergenza
Un sistema iperconvergente (spesso abbreviato HCI) è un’infrastruttura IT all-in-one che integra in un’unica soluzione tutti gli elementi fondamentali di un data center, tra cui storage, calcolo (RAM e CPU), rete e virtualizzazione.
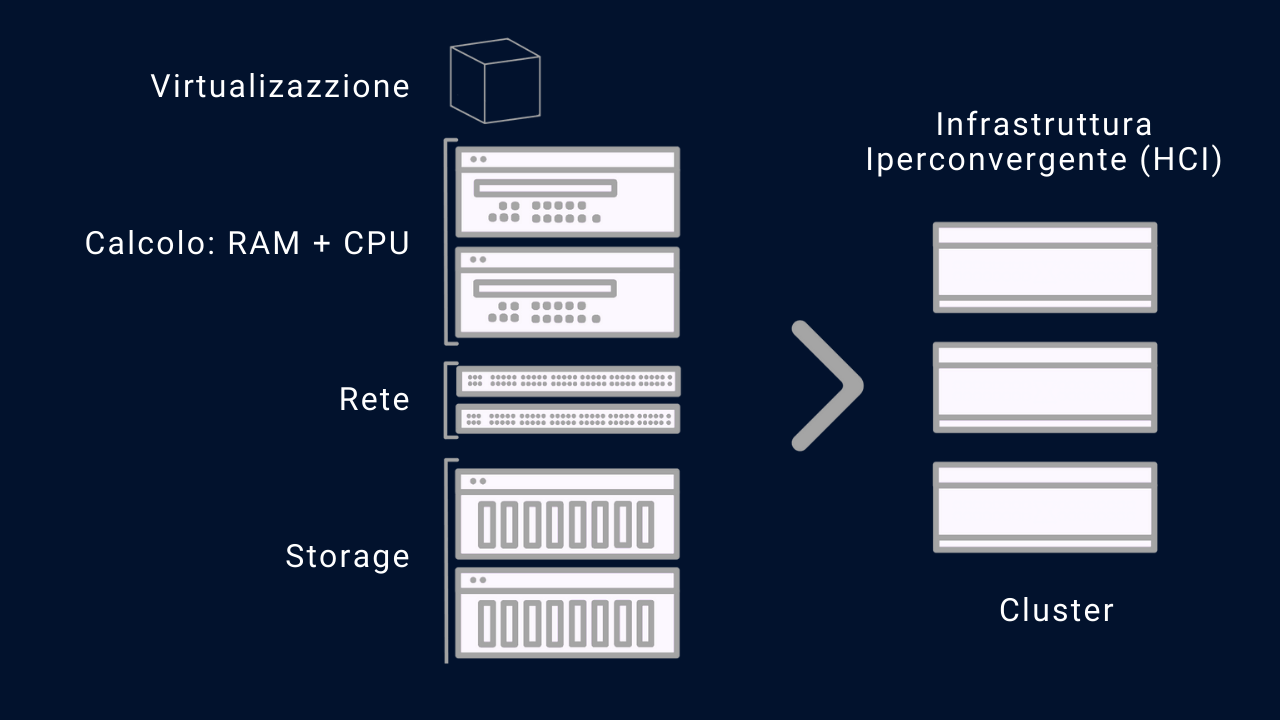
Possiamo dire che è l’insieme di server (detti nodi) e di switch che ne interconnettono le risorse per creare un’unica entità di elaborazione, ovvero un oggetto che è la somma di tutte le risorse dei nodi che chiameremo cluster.
Immagina un diagramma con 4 blocchi (o pool) interconnessi: il blocco dello storage, il blocco del calcolo (RAM e CPU) e il blocco della rete. Ogni blocco rappresenta una componente fondamentale dell’iperconvergenza.
Nel blocco dello storage, si troveranno un insieme di dispositivi di storage come dischi rigidi e unità a stato solido. Questi dispositivi verranno raggruppati in un pool condiviso e virtualizzato, creando un oggetto software-defined. Ciò significa che la capacità di storage di tutti i dispositivi viene combinata e distribuita tra i nodi del cluster iperconvergente.
Nel blocco del calcolo, esisteranno una serie di nodi, ognuno dei quali combina risorse di calcolo come memoria RAM e CPU. Ogni nodo del cluster funge da unità di elaborazione, in grado di eseguire le applicazioni e i carichi di lavoro. Grazie alla virtualizzazione, i carichi di lavoro possono essere distribuiti in modo dinamico tra i nodi, in base alle esigenze di prestazioni e di ridondanza. Ciò consente una gestione efficiente delle risorse e una maggiore agilità operativa.
Nel blocco della rete, essa è virtualizzata e gestita in modo Software-Defined Networking (SDN). Ciò significa che la configurazione e il controllo della stessa avvengono attraverso software, anziché attraverso dispositivi di rete fisici tradizionali. Le reti virtuali consentono una maggiore flessibilità e scalabilità, semplificando la gestione delle comunicazioni all’interno del cluster iperconvergente. La virtualizzazione della rete consente anche un’implementazione più efficace dell’isolamento e della sicurezza delle reti, proteggendo i dati e le applicazioni.
Questi tre blocchi – storage, calcolo e rete – sono interconnessi e lavorano insieme per creare un’infrastruttura iperconvergente. I dati vengono archiviati e gestiti nel pool di storage virtualizzato, i carichi di lavoro vengono eseguiti e distribuiti dinamicamente tra i nodi del cluster di calcolo, e le comunicazioni avvengono attraverso una rete virtualizzata.
Per semplificare al massimo il concetto facciamo un esempio con dei componenti comuni, ovvero dei server (nodi) e degli switch che li interconnettono:
Immaginiamo di avere 3 nodi identici, aventi ciascuno caratteristiche uguali, tra loro sono interconnessi con uno o più switch. L’iperconvergenza, unita alla virtualizzazione, farà sì che il sistema risultante che chiameremo Cluster (o più genericamente piattaforma iperconvergente) sia la sommatoria di tutte le componenti dei nodi e degli switch. Quindi un unico sistema (il cluster) metterà a disposizione delle applicazioni le risorse di calcolo, ovvero storage, RAM, CPU e rete. Tutte le risorse saranno a disposizione delle applicazioni mediante l’astrazione di un layer software che approfondiremo di seguito.
Cominciamo esaminando i tre pilastri principali dell’iperconvergenza ovvero storage, calcolo e rete.
3.1 Storage Iperconvergente
Lo storage iperconvergente integra lo storage di ciascun nodo all’interno della piattaforma iperconvergente, insieme alle risorse di calcolo e di rete. In altre parole, tutte le risorse necessarie per gestire le applicazioni e i dati sono fornite da un singolo sistema, rendendo l’infrastruttura più semplice da gestire e scalare.
Le principali caratteristiche dello storage iperconvergente includono:
- Architettura Scale-Out: Lo storage iperconvergente utilizza un’architettura scale-out, in cui nuovi nodi possono essere facilmente aggiunti per aumentare la capacità di storage. Questo permette di scalare l’infrastruttura in modo modulare, senza la necessità di investire in grandi quantità di storage in anticipo.
- Ridondanza e Alta Disponibilità: Lo storage iperconvergente offre livelli di ridondanza per garantire la disponibilità dei dati anche in caso di guasti hardware. I dati vengono replicati su più nodi all’interno del cluster, consentendo il recupero rapido e senza interruzioni in caso di problemi.
- Gestione Centralizzata: Lo storage iperconvergente è gestito tramite un’interfaccia centralizzata che permette di controllare tutte le risorse di storage e di monitorare le prestazioni dell’infrastruttura. Questo semplifica la gestione e riduce la complessità operativa.
- Virtualizzazione dello Storage: Lo storage iperconvergente utilizza tecniche di virtualizzazione per creare uno strato astratto tra l’hardware di storage sottostante e le applicazioni. Questo permette di fornire pool di storage virtuali che possono essere facilmente assegnati alle macchine virtuali o alle applicazioni che ne hanno bisogno.
- Facilità di Gestione: Lo storage iperconvergente è progettato per essere facilmente gestibile anche da personale IT con meno esperienza. L’automazione delle attività operative e la gestione centralizzata semplificano le operazioni quotidiane e riducono i tempi di configurazione e manutenzione.
- Flessibilità nell’Utilizzo: Lo storage iperconvergente offre la possibilità di allocare dinamicamente le risorse di storage in base alle esigenze delle applicazioni. Ciò consente di ottimizzare l’utilizzo dello spazio e di ridurre gli sprechi di risorse.
- Prestazioni Ottimizzate: Lo storage iperconvergente è progettato per garantire alte prestazioni, grazie alla ridondanza dei dati e alla distribuzione intelligente delle operazioni di I/O su più nodi. Ciò permette di supportare carichi di lavoro intensi senza degradare le prestazioni.
4. Networking Iperconvergente
Il networking è un elemento cruciale di un sistema iperconvergente, poiché è responsabile della connettività tra tutti i nodi dell’infrastruttura, consentendo la comunicazione e lo scambio di dati tra i diversi componenti. La rete iperconvergente è progettata per supportare le esigenze di alta disponibilità, prestazioni elevate e scalabilità dell’infrastruttura.
Ecco come viene gestita la rete in un sistema iperconvergente:
- Networking Virtuale: Nella rete iperconvergente, il networking è spesso virtualizzato, esattamente come un semplice sistema di virtualizzazione a nodo singolo. Consente la creazione di reti virtuali isolate all’interno del cluster. Queste reti virtuali possono essere configurate per diversi scopi, come la separazione di carichi di lavoro, la gestione del traffico, o la segmentazione per motivi di sicurezza.
- Integrazione della Rete con i Nodi: La rete è strettamente integrata con i nodi dell’infrastruttura iperconvergente. Ogni nodo ha interfacce di rete multiple, che sono utilizzate in modo dedicato per:
- la comunicazione tra i nodi stessi
- la gestione dell’infrastruttura
- la connettività tra le risorse virtuali e il resto del mondo.
- Load Balancing: La rete iperconvergente utilizza tecniche di bilanciamento del carico per distribuire il traffico in modo uniforme tra i nodi. Questo permette di ottimizzare l’utilizzo delle risorse di rete e di evitare congestioni o punti di debolezza.
- Fault Tolerance: Per garantire l’alta disponibilità, la rete iperconvergente utilizza la ridondanza e la failover automatica. In caso di guasto di un nodo o di un’interfaccia di rete, il traffico viene automaticamente reindirizzato verso percorsi alternativi per evitare interruzioni del servizio.
- Gestione Centralizzata: La gestione della rete è centralizzata attraverso un’interfaccia di amministrazione unificata. Questo consente agli amministratori di monitorare le prestazioni di rete, configurare le reti virtuali e gestire le politiche di sicurezza in modo semplice e coerente.
- QoS (Quality of Service): La rete iperconvergente può implementare il QoS per garantire che le applicazioni e i carichi di lavoro critici ricevano la priorità sul traffico meno critico. Ciò permette di ottimizzare le prestazioni e garantire che le applicazioni importanti non siano degradate da altre attività di rete meno cruciali.
- Utilizzo del protocollo LACP (Link Aggregation Control Protocol) è ampiamente utilizzato nei sistemi iperconvergenti per fornire una maggiore disponibilità e capacità di larghezza di banda nella rete. LACP consente di aggregare fisicamente più porte di rete in un singolo canale logico, aumentando la capacità di trasferimento dei dati e fornendo ridondanza per garantire la continuità operativa.

