In questo articolo ti mostreremo come aggiornare Proxmox 7.0, partendo da una versione 6.4, e Ceph Pacific 16.2.4
Contenuti dell’articolo:
- Ambiente utilizzato per aggiornare Proxmox e Ceph
- Novità Proxmox 7.0
- Passi propedeutici per l’aggiornamento Proxmox 7.0
- Come aggiornare Proxmox 6.4-13
- Come aggiornare Ceph Octopus 15.2
- Come aggiornare Proxmox 7.0
- Come aggiornare Ceph Pacific 16.2.4
- Siamo partiti da un cluster 6.4-6
- Ceph versione Nautilus 15.2
Hardware utilizzato:
L’aggiornamento viene fatto sul Cluster Proxmox 3 Nodi con Ceph
Leggi anche Come creare un Cluster Proxmox con Ceph
Qui di seguito troverai le principali novità.
- QEMU 6.0 con io_uring per gestione dei dischi delle VM senza riferimenti
- OpenZFS 2.0.4
- Nuovo Ceph Pacific 16.2
- Storage Btrfs con snapshot, build-in RAID.
- Gestione repository da interfaccia web
- Single Sign-on con OpenID Connect
- Plugin per supporto dual stack IPV4 e IPV6
- Ifupdown2 istallato di default
- chrony come demone NTP di default
- Bug fixed in generale
In questa guida ufficiale puoi trovare tutte le informazioni più nello specifico.
- Passi propedeutici per l’aggiornamento Proxmox 7.0
Per aggiornare Proxmox 7.0, occorre seguire dei passi ben precisi ed avere, al momento dell’aggiornamento, un ambiente con:
- Proxmox 6 ultima versione disponibile (per noi la 6.4-13)
- Ceph Octopus 15.2
Una volta che abbiamo l’ambiente configurato in questo modo, potremmo continuare con l’aggiornamento Proxmox e Ceph.
Per verificare la versione di Ceph, eseguire il comando
Come aggiornare Proxmox 6.4-13
Aggiornare proxmox usando la solita procedura da interfaccia web oppure esegure da riga di comando
- Aggiornamento Ceph Octopus 15.2
Attenzione. Questi sono passi da fare parallelamente su tutti i nodi.
a. Aggiornare i repository alla versione Octopus, eseguire (ogni nodo):
b. Verificare che sia stato aggiornato correttamente il file
c. Settare il flag ‘noout’, eseguire (ogni nodo):
d. Eseguire l’aggiornamento (ogni nodo)
e. Controllo stato Ceph
Dopo il comando apt full-upgrade, vediamo che lo stato di Ceph risulta essere OK, ma suggerisce di riavviare i servizi per attivare la nuova versione.
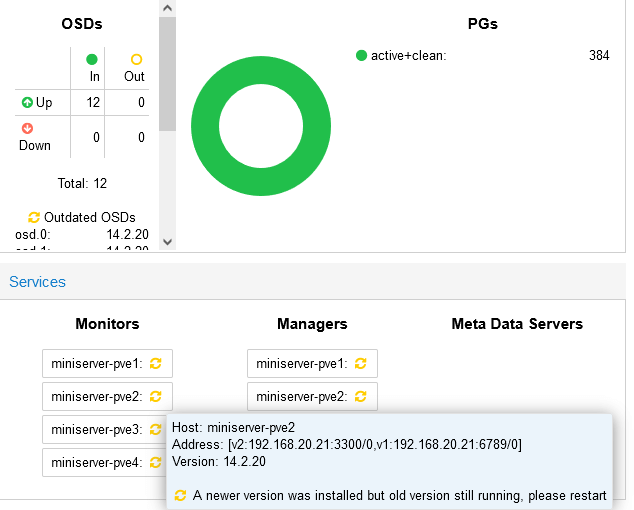
f. È necessario ora riavviare i monitor ceph, eseguire (ogni nodo)
Dalla dashboard verificare lo stato dei Monitors e Managers
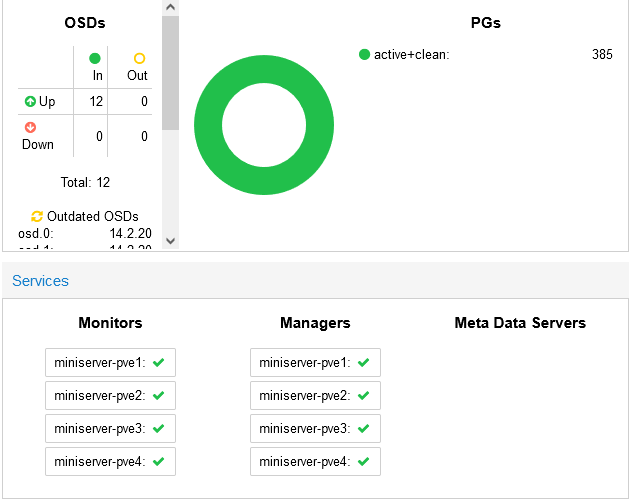
g. Verificare che l’aggiornamento di ogni monitor sia completato
Verificare che l’output sia una cosa del tipo
h. Riavviare il ceph manager, eseguire (ogni nodo)
i. Verificare che ogni ceph manager sia running, eseguendo
j. Riavviamo ora ogni OSD separatamente per ogni nodo, eseguendo (ogni nodo).
Attenzione: dopo aver lanciato il comando sul nodo, attendi che tutti i PG siano nello stato di “active+clean”. Una volta che sono tutti “active+clean” passa al nodo successivo.
k. Verificatiamo lo stato del cluster, o da Dashboard di Ceph oppure eseguendo il comando
Controllare che sia nello stato di HEALTH_OK. È possibile che sia anche nello stato
HEALTH_WARN
noout flag(s) set
Ma nulla di preoccupante
l. Disabilitare la conversione automatica, eseguendo (ogni nodo)
m. Abilitare Octopus, eseguendo
n. De-settare il flag ‘noout’, eseguire (ogni nodo)
o. Se sono presenti dei messaggi di HEALTH inerenti a Ceph, eseguire
p. Anche se non sono presenti alert, è consigliabile passare ogni CRUSH buckets a straw2, in quale era stato aggiunto nella release Hammer. Eseguire
q. In caso di problemi è possibile tornare al backp precedente, eseguendo
r. Abilitare il protocollo di rete v2, eseguendo (ogni nodo)
Verificare che vi sia anche la v2, oltre che la v1, eseguendo
s. Abilitare PG autoscaling
Prima di abilitare l’autoscaling bisogna sapere che una volta abilitato, i PG vengono ribilanciati (se necessario) provocando traffico sulla cluster network di Ceph, consumando risorse dell’host.
Per abilitarlo, eseguire
t. Nel caso in cui ci fossero degli HEALTH warnings del tipo
- client is using insecure global_id reclaim
- mons are allowing insecure global_id reclaim
Migra tutte le macchine presenti sul nodo su un altro nodo disponibile, per poi eseguire il comando
Per non mostrare più il messaggio di warning, eseguire
A questo punto abbiamo aggiornato Ceph alla versione Octopus.
Dopo tutta la procedura, è possibile che vi trovate Ceph nello stato di HEATH_WARN, con il messaggio “2 pools have too many placement groups”
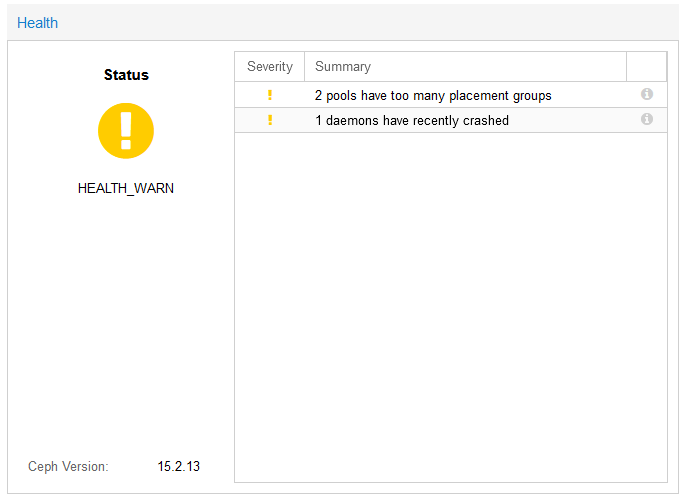
Questo avviene perché la funzione PG autoscale è settato su “warn”

Nella modalità Autoscale = warn, vengono suggeriti il numero di PG che secondo Ceph sarebbe corretto settare all’interno del pool.
Ad esempio, vediamo in figura sopra che per i pool ceph_pool_ssd e ceph_pool_hdd vengono suggeriti 32 e 64 PG rispettivamente.
Il numero di PG suggerito dipende fondamentalmente da:
- Target Ratio
- Target Size
Per più informazioni su questo argomento ti consiglio di vedere il video qui sotto.
- Aggiornamento Proxmox 7.0
Raccomandiamo di eseguire l’aggiornamento di ogni nodo attraverso connessione SSH, in quanto durante l’aggiornamento è normale perdere la connessione con la console offerta dalla GUI.
a. Controllo con tool pve6to7
Proxmox mette a disposizione un tool che esegue in automatico un controllo sul sistema, evidenziando potenziali problemi o incongruenze se presenti.
Eseguire
Eseguire questo controllo almeno una volta prima dell’aggiornamento e una volta dopo l’aggiornamento stesso.
b. Spostamento delle VM e Container
Consigliamo di migrare le VM e Container prima di aggiornare un nodo.
Notare che la migrazione delle macchine da una versione Proxmox più vecchia (6.4) verso una versione più recente (7.0) non comporta rischi, mentre viceversa potrebbero esserci dei problemi. Da tenere sempre in mente quando si aggiorno il cluster.
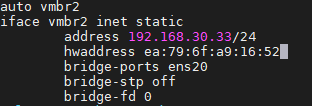
c. Cambio dei MAC address dei Linux Bridge
È possibile che i MAC address dei Linux Bridge possano cambiare dopo l’aggiornamento. Se stai usando un hosting il quale usa un meccanismo di anti-spoofing è possibile che avrai dei problemi dopo l’aggiornamento, in quanto l’hosting dovrà essere avvisato dei nuovi MAC address.
Per evitare questo, scrivi in modo esplicito il MAC address all’interno del file di configurazione /etc/network/interfaces in questo modo
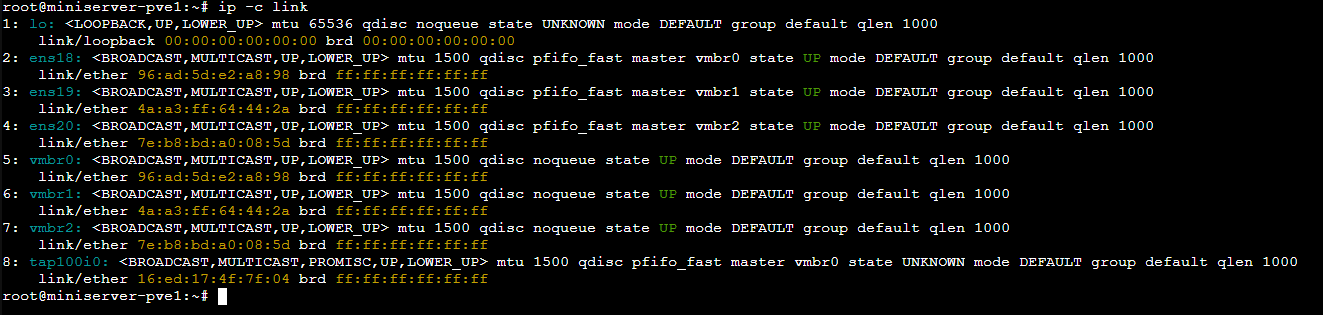
Aiutati con il comando ip -c link per capire quali sono i MAC address dei Linux Bridge
d. Aggiornamento repository APT
Da eseguire su tutti i nodi del cluster
e. Aggiunta dei repository Proxmoxm VE 7
Per un ambiente di produzione usare la versione enterprise, eseguendo (ogni nodo):
Per un ambiente non di produzione, usiamo i no-subscription andando solamente ad editare il file /etc/apt/sources.list in questo modo:
deb http://ftp.debian.org/debian bullseye main contrib
deb http://ftp.debian.org/debian bullseye-updates main contrib
PVE pve-no-subscription repository provided by proxmox.com,
NOT recommended for production use
deb http://download.proxmox.com/debian/pve bullseye pve-no-subscription
security updates
deb http://security.debian.org/debian-security bullseye-security main contrib
Per correttezza, andiamo a commentare i repository nel file /etc/apt/sources.list.d/pve-enterprise.list in modo da essere sicuri che non vengano cosiderati.
f. Backports
Attenzione a non lasciare delle backport nel file /etc/apt/sources.list perché i pacchetti non sono dati testati.
g. Modifica repository per Ceph
Eseguire (ogni nodo)
echo “deb http://download.proxmox.com/debian/ceph-octopus bullseye main” > /etc/apt/sources.list.d/ceph.list
h. Aggiornamento a Debian Bullseye e Proxmox VE 7.0
Attenzione: fate l’aggiornamento un nodo alla volta prima di lanciare questi due comandi su un altro nodo.
Durante l’aggiornamento compare un Warning, accettate senza problemi:

Vi verranno mostrate anche le apt-listchanges: News. Premere q e proseguire.
Selezionare la lingua della tastiera quando richiesto
Mantenere la corrente versione, quindi mettere “N”
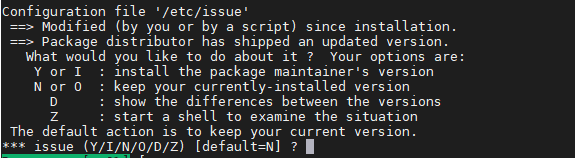
Selezionare “Yes” se si vuole permettere al sistema si eseguire dei restart dei servizi senza chiedere il permesso (scelta più smart), altrimenti selezionare “No”. 
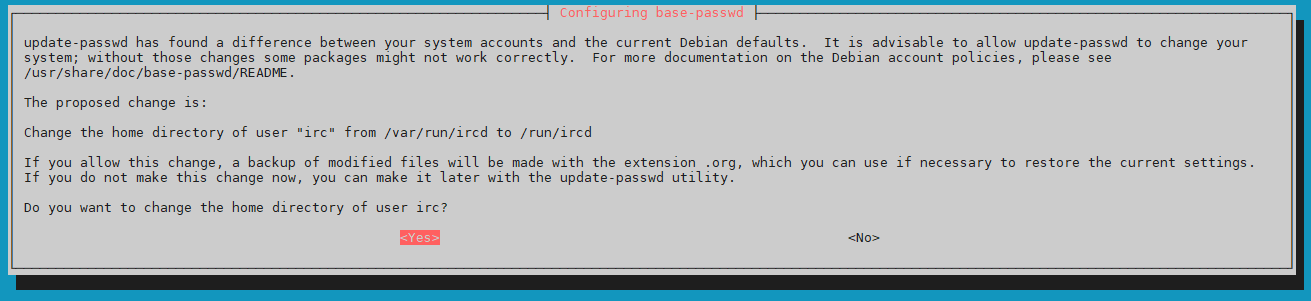
Permettere il cambiamento della home directory per utente irc
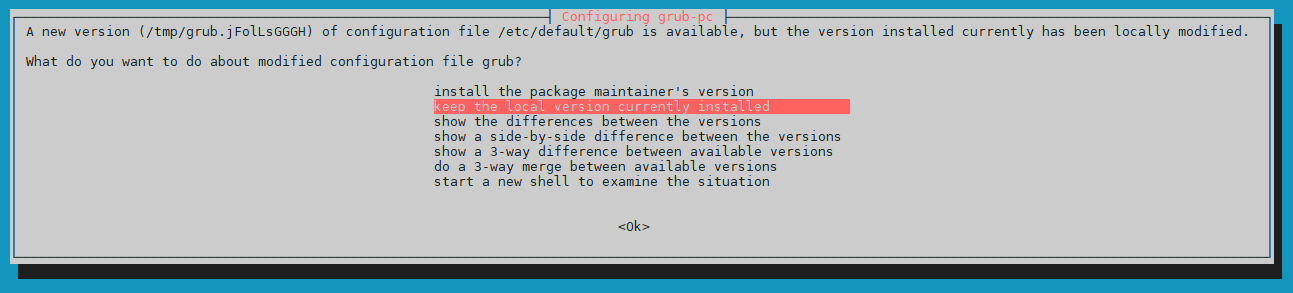
Specificare se mantenere la corrente versione di grub o installare la nuova versione
Se richiesto, specificate se volete mantenere la corrente versione del file /etc/ssh/sshd_config
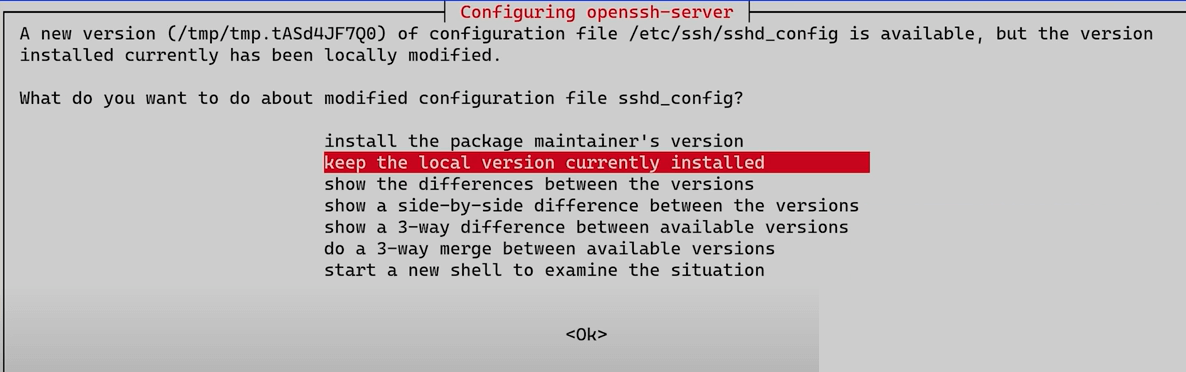
Mantenere il corrente file /etc/apt/sources.list.d/pve-enterprise.list
se ad esempio si stanno usando i repository no-pve-subscription, altrimenti mettere “Y”
Al termine dell’istallazione, eseguire nuovamente il controllo per quel nodo con
Se non ci sono errori, procedere con il reboot del nodo.
Anche dopo il reboot, eseguire nuovamente il controllo con
Rifare il punto (h) per tutti i nodi del cluster, migrando su un altro nodo le VM e Container.
- Aggiornamento Ceph Pacific 16.2.4
Una volta che siamo passati a Proxmox 7 e verificato che sia tutto ok sulla nostra infrastruttura, siamo pronti per passare a Ceph Pacific.
Ricordiamo che per passare a Pacific dobbiamo avere:
- Proxmox 7
- Ceph Octopus
a. Attivazione msgrv2
Già fatto nei passi precedenti durante il passaggio da Nautilus a Octopus. Per chi non lo avesse ancora datto, eseguire
b. Modifica dei repository
Esegure il comando per modificare i repository (ogni nodo)
Controllare che il file /etc/apt/sources.list.d/ceph.list sia stato modificato in questo modo
deb http://download.proxmox.com/debian/ceph-pacific bullseye main
c. Settare il flag ‘noout’
Raccomandiamo di settare il flag con il comando
d. Aggiornamento di ogni nodo
Eseguire i due comandi seguenti su tutti i nodi del cluster
e. Restart dei Monitor
Riavviamo i monitor (ogni nodo)
Verifichiamo che l’aggiornamento dei monitor sia alla versione 16, con il comando
f. Restart dei Manager
Riavviamo i Manage (ogni nodo)
Verifichiamo se sono running con
g. Restart degli OSD
Riavviamo gli OSD (ogni nodo)
controlliamo lo stato con
h. Abilitiamo Pacific e disabilitiamo tutto quello più vecchio
i. Unset del flag ‘noout’
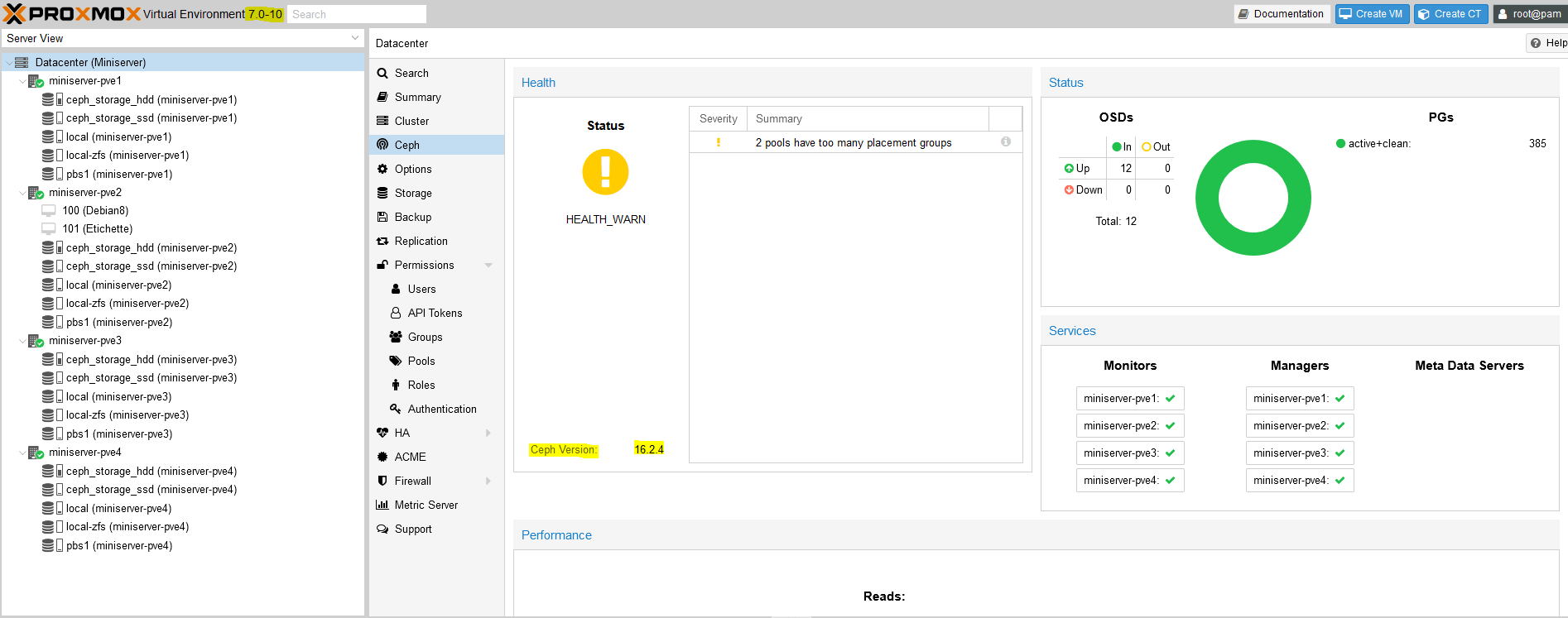
Lo stato finale di e quello mostrato qui sotto, in cui abbiamo Ceph Version 16.2.4 e con tutti PG allo stato active+clean e Proxmox versione 7.0-10